顶点位置可能是顶点信息中最重要的部分。顶点着色器必须生成的唯一数据是裁剪空间顶点位置的计算;其他所有内容都是用户定义的。
计算适当的顶点位置可以将一组三角形变成类似于真实物体的东西。本书的这一部分将详细介绍如何让物体移动,以及如何将它们呈现为三维物体。它涵盖了如何通过一系列空间操纵顶点位置,以实现诸如改变观看者方向之类的概念。它还涵盖了如何任意定位和定向物体,以实现多种不同类型的运动和动画。
第 3 章 OpenGL 的移动三角形
本教程介绍如何移动物体。它将介绍新的着色器技术。
移动顶点
人们可能认为移动三角形或其他对象的最简单方法是直接修改顶点位置数据。从之前的教程中,我们了解到顶点数据存储在缓冲区对象中。因此,任务是修改缓冲区对象中的顶点数据。这就是它的作用 CPUPositionOffset.cpp 。
修改分两步完成。第一步是生成将应用于每个位置的 X、Y 偏移量。第二步是将该偏移量应用于每个顶点位置。偏移量的生成使用以下函数完成 ComputePositionOffset:
例 3.1. 位置偏移的计算
void ComputePositionOffsets(float &fXOffset, float &fYOffset)
{
const float fLoopDuration = 5.0f;
const float fScale = 3.14159f * 2.0f / fLoopDuration;
float fElapsedTime = glutGet(GLUT_ELAPSED_TIME) / 1000.0f;
float fCurrTimeThroughLoop = fmodf(fElapsedTime, fLoopDuration);
fXOffset = cosf(fCurrTimeThroughLoop * fScale) * 0.5f;
fYOffset = sinf(fCurrTimeThroughLoop * fScale) * 0.5f;
}此函数循环计算偏移量。偏移量产生圆周运动,并且每 5 秒(由 控制 fLoopDuration)偏移量将到达圆周的起点。该函数 glutGet(GLUT_ELAPSED_TIME) 检索自应用程序启动以来的整数时间(以毫秒为单位)。该 fmodf 函数计算时间的浮点模数。通俗地说,它采用第一个参数并返回该参数与第二个参数相除的余数。因此,它返回范围为 [0, fLoopDuration) 的值,这正是我们创建周期性重复模式所需要的。
cosf 和函数 sinf 分别计算余弦和正弦。了解这些函数的具体工作原理并不重要,但它们可以有效地计算直径为 2 的圆。通过乘以 0.5f,它将圆缩小为直径为 1 的圆。
一旦计算出偏移量,就必须将偏移量添加到顶点数据中。这可以通过以下 AdjustVertexData 函数完成:
例 3.2. 调整顶点数据
{
std::vector<float> fNewData(ARRAY_COUNT(vertexPositions));
memcpy(&fNewData[0], vertexPositions, sizeof(vertexPositions));
for(int iVertex = 0; iVertex < ARRAY_COUNT(vertexPositions); iVertex += 4)
{
fNewData[iVertex] += fXOffset;
fNewData[iVertex + 1] += fYOffset;
}
glBindBuffer(GL_ARRAY_BUFFER, positionBufferObject);
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(vertexPositions), &fNewData[0]);
glBindBuffer(GL_ARRAY_BUFFER, 0);
}此函数的工作原理是将顶点数据复制到 std::vector 中,然后将偏移量应用于每个顶点的 X 和 Y 坐标。最后三行是与 OpenGL 相关的部分。
首先,将包含位置的缓冲区对象绑定到上下文。然后 glBufferSubData 调用新函数将该数据传输到缓冲区对象。
glBufferData 和 之间的区别 glBufferSubData 在于 SubData 函数不 _ 分配 _ 内存。glBufferData 专门分配一定大小的内存;glBufferSubData 仅将数据传输到已经存在的内存。调用 glBufferData 已分配的缓冲区对象会告诉 OpenGL _ 重新分配 _ 此内存,丢弃先前的数据并分配新的内存块。而调用 glBufferSubData 尚未分配内存的缓冲区对象 glBufferData 则会出现错误。
可以将 视为和 glBufferData 的组合 ,而 glBufferSubData 只是。malloc``memcpy``memcpy
该 glBufferSubData 函数只能更新缓冲区对象内存的一部分。该函数的第二个参数是开始复制到缓冲区对象的字节偏移量,第三个参数是要复制的字节数。第四个参数是要复制到缓冲区对象该位置的字节数组。
函数的最后一行只是解除缓冲区对象的绑定。这不是绝对必要的,但在绑定后清理绑定是一种好的做法。
缓冲区对象使用提示。 每次我们绘制某些东西时,我们都会更改缓冲区对象的数据。OpenGL 有一种方法可以告诉它您将执行此类操作,这就是 的最后一个参数的目的 glBufferData。本教程稍微改变了缓冲区对象的分配,替换了:
glBufferData(GL_ARRAY_BUFFER,sizeof(vertexPositions),vertexPositions,GL_STATIC_DRAW);
替换为:
glBufferData(GL_ARRAY_BUFFER,sizeof(vertexPositions),vertexPositions,GL_STREAM_DRAW);
GL_STATIC_DRAW 告诉 OpenGL 您打算只设置一次此缓冲区对象中的数据。GL_STREAM_DRAW 告诉 OpenGL 您打算持续设置此数据,通常每帧一次。这些参数对于 API 没有 _ 任何 _ 意义;它们只是对 OpenGL 实现的提示。在频繁更改时,正确使用这些提示对于获得良好的缓冲区对象性能至关重要。我们稍后会看到更多这些提示。
渲染函数现在变成了这样:
例 3.3. 更新并绘制顶点数据
void display()
{
float fXOffset = 0.0f, fYOffset = 0.0f;
ComputePositionOffsets(fXOffset, fYOffset);
AdjustVertexData(fXOffset, fYOffset);
glClearColor(0.0f, 0.0f, 0.0f, 0.0f);
glClear(GL_COLOR_BUFFER_BIT);
glUseProgram(theProgram);
glBindBuffer(GL_ARRAY_BUFFER, positionBufferObject);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 4, GL_FLOAT, GL_FALSE, 0, 0);
glDrawArrays(GL_TRIANGLES, 0, 3);
glDisableVertexAttribArray(0);
glUseProgram(0);
glutSwapBuffers();
glutPostRedisplay();
}前三行获取偏移量并设置顶点数据。除了最后一行之外,其余内容与第一个教程相同。函数的最后一行用于告诉 FreeGLUT 不断调用 display。通常, display 只有在窗口大小发生变化或窗口未被覆盖时才会调用。glutPostRedisplay 导致 FreeGLUT 再次调用 display。不是立即调用,但速度相当快。
如果您运行本教程,您将看到一个较小的三角形(本教程中尺寸已缩小)在一个圆圈内滑动。
更好的方法
对于 3 个顶点的示例来说,这没问题。但想象一下涉及数百万个顶点的场景(不,对于高端应用程序来说这并不夸张)。以这种方式移动对象意味着必须从原始顶点数据中复制数百万个顶点,为每个顶点添加偏移量,然后将该数据上传到 OpenGL 缓冲区对象。所有这些都是在渲染 _ 之前 _ 完成的。显然一定有更好的方法;游戏不可能每帧都这样做,同时仍能保持不错的帧率。
实际上,他们确实这么做了很长一段时间。在 GeForce 256 出现之前,所有游戏都是这样运作的。图形硬件只是获取剪辑空间中的顶点列表,然后将其栅格化为片段和像素。诚然,在那些日子里,我们谈论的可能是每帧 10,000 个三角形。尽管从那时起 CPU 已经取得了长足的进步,但它们并没有随着图形场景的复杂性而扩展。
GeForce 256(注意:不是 GT 2xx 卡,而是第一款 GeForce 卡)是第一款真正进行顶点处理的显卡。它可以将顶点存储在 GPU 内存中,读取它们,对它们进行某种转换,然后将它们发送到其余的管道。旧款 GeForce 256 可以进行的转换类型非常有用,但相当简单。
借助现代硬件和 OpenGL 3.x,我们拥有了更加灵活的东西:顶点着色器。
记住我们在做什么。我们计算一个偏移量。然后我们将该偏移量应用于每个顶点位置。顶点着色器被赋予每个顶点位置。因此,只需为顶点着色器提供偏移量并让它计算最终的顶点位置就很有意义了,因为它对每个顶点进行操作。这就是所做的 VertPositionOffset.cpp。
顶点着色器可以在 中找到 data\positionOffset.vert。这里使用的顶点着色器如下:
例 3.4. 偏移顶点着色器
#version 330
layout(location = 0) in vec4 position;
uniform vec2 offset;
void main()
{
vec4 totalOffset = vec4(offset.x, offset.y, 0.0, 0.0);
gl_Position = position + totalOffset;
}
定义输入 后 position,着色器定义一个二维向量 offset。但它用术语 来定义它 uniform,而不是 in 或 out。这具有特殊含义。
着色器和粒度。 回想一下,每次执行着色器时,着色器都会为定义为的变量获取新值 in。每次调用顶点着色器时,它都会从顶点属性数组和缓冲区获取一组不同的输入。这对于顶点位置数据很有用,但这不是我们想要的偏移量。我们希望每个顶点使用 _ 相同的 _ 偏移量;如果您愿意的话,可以称之为“统一” 偏移量。
定义为 的变量 uniform 不会以与定义为 的变量相同的频率更改 in。输入变量会随着着色器的每次执行而更改。统一变量(称为 uniforms)仅在渲染调用执行之间更改。即便如此,它们也只会在用户将其明确设置为新值时更改。
顶点着色器输入来自顶点属性数组定义和缓冲区对象。相比之下,uniform 直接在程序对象上设置。
为了在程序中设置统一值,我们需要两样东西。首先是统一值位置。与属性非常相似,有一个索引指向特定的统一值。与属性不同,您无法自己设置此位置;您必须查询它。在本教程中,这是在函数中完成的 InitializeProgram,使用以下行:
offsetLocation = glGetUniformLocation(theProgram, "offset");
该函数 glGetUniformLocation 检索由第二个参数命名的统一的统一位置。请注意,仅仅因为统一是在着色器中定义的,GLSL 不必 _ 为其 _ 提供位置。只有当统一在程序中实际使用时,它才会有一个位置,就像我们在顶点着色器中看到的那样;glGetUniformLocation 如果统一没有位置,则将返回 -1。
一旦我们有了统一的位置,我们就可以设置统一的值。但是,与检索统一位置不同,设置统一的值需要程序当前正在使用 glUseProgram。因此,渲染代码如下所示:
例 3.5. 使用计算偏移量进行绘制
void display()
{
float fXOffset = 0.0f, fYOffset = 0.0f;
ComputePositionOffsets(fXOffset, fYOffset);
glClearColor(0.0f, 0.0f, 0.0f, 0.0f);
glClear(GL_COLOR_BUFFER_BIT);
glUseProgram(theProgram);
glUniform2f(offsetLocation, fXOffset, fYOffset);
glBindBuffer(GL_ARRAY_BUFFER, positionBufferObject);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 4, GL_FLOAT, GL_FALSE, 0, 0);
glDrawArrays(GL_TRIANGLES, 0, 3);
glDisableVertexAttribArray(0);
glUseProgram(0);
glutSwapBuffers();
glutPostRedisplay();
}我们用它 ComputePositionOffsets 来获取偏移量,然后用它 glUniform2f 来设置统一的值。缓冲区对象的数据永远不会改变;着色器只是做了艰苦的工作。这就是这些着色器阶段存在的原因。
标准 OpenGL 术语
该函数 glUniform2f 使用了 OpenGL 命名法的一个特殊部分。具体来说,就是“ 2f ”部分。
Uniform 可以有不同的类型。由于 OpenGL 是用 C 而不是 C++ 定义的,因此没有函数重载的概念。因此,执行相同操作但采用不同类型的函数必须具有不同的名称。OpenGL 已为这些函数标准化了其命名约定。
函数类似 glUniform 有后缀。后缀的第一部分是它所取值的数量。在上述情况下, glUniform2f 除了常规参数外,还取 2 个值。基本 glUniform 参数只是统一位置,因此 glUniform2f 取一个统一位置和两个值。
它所接受的值的类型由第二部分定义。可能的类型名称及其关联类型为:
| b | signed byte | ub | unsigned byte |
| s | signed short | us | unsigned short |
| i | signed int | ui | unsigned int |
| f | float | d | double |
请注意,OpenGL 对所有这些类型都有特殊的 typedef。例如,GLfloat 是 float 的 typedef 。这对于简单类型来说不是特别有用,但对于整数类型,它们非常有用。
并非所有接受多种类型的函数都会接受所有可能的类型。例如, glUniform 仅提供 i、 ui 和 f 变体(OpenGL 4.0 引入了 d 变体)。
还有向量形式,通过在类型后添加“ v ”来定义。它们采用一个值数组,并带有一个参数来表示数组中有多少个元素。因此,该函数 glUniform2fv 采用统一的位置、一定数量的条目和一个包含相同数量条目的数组。每个条目的大小为 _ 两个浮点数 _;条目数不是浮点数或其他类型的数量。它是值的数量除以每个条目的值的数量。由于“ 2f ”代表两个浮点数,因此这就是每个条目中有多少个值。
有些 OpenGL 函数只接受类型而不接受数字。这些函数接受固定数量的该类型的参数,通常只有一个。
矢量数学。 你可能对这些线的工作原理感到好奇:
vec4 totalOffset = vec4(offset.x, offset.y, 0.0, 0.0);
gl_Position = position + totalOffset;这里看起来像函数的 vec4 是一个构造函数;它从 4 个浮点数创建一个 vec4。这样做是为了使加法更容易。
position 的加法 totalOffset 是逐个组件的加法。这是执行此操作的简便方法:
gl_Position .x = 位置.x + 总偏移量.x; gl_Position .y = 位置.y + 总偏移量.y; gl_Position .z = 位置.z + 总偏移量.z; gl_Position .w = 位置.w + 总偏移量.w;
GLSL 内置了大量向量数学运算。当应用于向量时,数学运算都是按分量进行的。但是,将不同维度的向量相加是非法的。所以你不能得到 vec2 + vec4。这就是为什么我们必须 offset 在执行加法之前将其转换为 vec4 的原因。
着色器更强大
我们不再需要手动转换顶点,这很好。但也许我们可以将更多东西移到顶点着色器。是否可以将所有东西都移到 ComputePositionOffsets 顶点着色器?
嗯,不行。对的调用 glutGet(GL_ELAPSED_TIME) 不能移到那里,因为 GLSL 代码不能直接调用 C/C++ 函数。但其他一切都可以移动。这就是它的作用 VertCalcOffset.cpp。
顶点程序位于 data\calcOffset.vert。
例 3.6. 偏移计算顶点着色器
#version 330
layout(location = 0) in vec4 position;
uniform float loopDuration;
uniform float time;
void main()
{
float timeScale = 3.14159f * 2.0f / loopDuration;
float currTime = mod(time, loopDuration);
vec4 totalOffset = vec4(
cos(currTime * timeScale) * 0.5f,
sin(currTime * timeScale) * 0.5f,
0.0f,
0.0f);
gl_Position = position + totalOffset;
}
该着色器采用两个统一值:循环持续时间和经过的时间。
在这个着色器中,我们使用了许多标准 GLSL 函数,例如 mod,cos 和 sin。我们 mix 在上一篇教程中看到过。这些只是冰山一角;还有许多 _ 可用 _ 的标准 GLSL 函数。
渲染代码看起来与之前的渲染代码非常相似:
例 3.7. 带时间的渲染
void display()
{
glClearColor(0.0f, 0.0f, 0.0f, 0.0f);
glClear(GL_COLOR_BUFFER_BIT);
glUseProgram(theProgram);
glUniform1f(elapsedTimeUniform, glutGet(GLUT_ELAPSED_TIME) / 1000.0f);
glBindBuffer(GL_ARRAY_BUFFER, positionBufferObject);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 4, GL_FLOAT, GL_FALSE, 0, 0);
glDrawArrays(GL_TRIANGLES, 0, 3);
glDisableVertexAttribArray(0);
glUseProgram(0);
glutSwapBuffers();
glutPostRedisplay();
}这次,我们不需要任何代码来使用经过的时间;我们只需将其不加修改地传递给着色器。
你可能想知道如何 loopDuration 设置 uniform。这是在我们的着色器初始化例程中完成的,并且只执行一次:
例 3.8. 循环持续时间设置
void InitializeProgram()
{
std::vector<GLuint> shaderList;
shaderList.push_back(Framework::LoadShader(GL_VERTEX_SHADER, "calcOffset.vert"));
shaderList.push_back(Framework::LoadShader(GL_FRAGMENT_SHADER, "standard.frag"));
theProgram = Framework::CreateProgram(shaderList);
elapsedTimeUniform = glGetUniformLocation(theProgram, "time");
GLint loopDurationUnf = glGetUniformLocation(theProgram, "loopDuration");
glUseProgram(theProgram);
glUniform1f(loopDurationUnf, 5.0f);
glUseProgram(0);
}我们像平常一样使用 获得时间统一 glGetUniformLocation。对于循环持续时间,我们在局部变量中获取它。然后我们立即设置当前程序对象,将统一设置为一个值,然后取消设置当前程序对象。
程序对象与所有包含内部状态的对象一样,将保留其状态,除非您明确更改它。因此的值 loopDuration 将永久为 5.0f;我们不需要每帧都设置它。
多个着色器
好吧,移动三角形很不错,但如果我们能在片段着色器中做一些基于时间的事情就更好了。片段着色器无法影响对象的位置,但可以控制其颜色。这就是它的作用 FragChangeColor.cpp。
本教程中的片段着色器从以下文件加载 data\calcColor.frag:
例 3.9. 基于时间的片段着色器
#version 330
out vec4 outputColor;
uniform float fragLoopDuration;
uniform float time;
const vec4 firstColor = vec4(1.0f, 1.0f, 1.0f, 1.0f);
const vec4 secondColor = vec4(0.0f, 1.0f, 0.0f, 1.0f);
void main()
{
float currTime = mod(time, fragLoopDuration);
float currLerp = currTime / fragLoopDuration;
outputColor = mix(firstColor, secondColor, currLerp);
}
此函数类似于顶点着色器中的周期性循环(与上次我们看到的相同)。它不使用 sin/cos 函数来计算圆的坐标,而是根据循环的距离在两种颜色之间进行插值。当它处于循环开始时,三角形将为 firstColor,当它处于循环结束时,它将为 secondColor。
标准库函数 mix 在两个值之间执行线性插值。与许多 GLSL 标准函数一样,它可以接受向量参数;它将对它们执行逐个分量的操作。因此,两个参数的四个分量中的每一个都将由第三个参数进行线性插值。 currLerp 在这种情况下,第三个参数是 0 到 1 之间的值。当它为 0 时,返回值 mix 将是第一个参数;当它为 1 时,返回值将是第二个参数。
以下是程序初始化代码:
例 3.10. 更多着色器创建
void InitializeProgram()
{
std::vector<GLuint> shaderList;
shaderList.push_back(Framework::LoadShader(GL_VERTEX_SHADER, "calcOffset.vert"));
shaderList.push_back(Framework::LoadShader(GL_FRAGMENT_SHADER, "calcColor.frag"));
theProgram = Framework::CreateProgram(shaderList);
elapsedTimeUniform = glGetUniformLocation(theProgram, "time");
GLint loopDurationUnf = glGetUniformLocation(theProgram, "loopDuration");
GLint fragLoopDurUnf = glGetUniformLocation(theProgram, "fragLoopDuration");
glUseProgram(theProgram);
glUniform1f(loopDurationUnf, 5.0f);
glUniform1f(fragLoopDurUnf, 10.0f);
glUseProgram(0);
} time 和前面一样,我们得到和的 统一位置 loopDuration,以及新的 fragLoopDuration。然后我们为程序设置两个循环持续时间。
您可能想知道如何 time 设置顶点着色器和片段着色器的统一值?GLSL 编译模型的优点之一是将顶点着色器和片段着色器链接在一起形成单个对象,相同名称和类型的统一值会连接在一起。因此,只有一个统一值位置 time,它引用两个着色器中的统一值。
缺点是,如果您在一个着色器中创建一个与另一个着色器中名称相同但类型不同的统一值,OpenGL 将给出链接器错误,并且无法生成程序。此外,可能会意外将两个统一值链接为一个。在本教程中,片段着色器的循环持续时间必须被赋予不同的名称,否则这两个着色器将共享相同的循环持续时间。
无论如何,由于这个原因,渲染代码是不变的。时间统一器每帧都会根据 FreeGLUT 的运行时间进行更新。
着色器中的全局变量。GLSL 中全局范围的变量可以用某些存储限定符来定义: const、、和 uniform。值的工作方式与 C99 和 C++ 中的方式相同:值不会改变,仅此而已。它必须有一个初始化程序。非限定变量的工作方式与 C/C++ 中预期的方式相同;它是一个可以更改的全局值。GLSL 着色器可以调用函数,并且全局变量可以在函数之间共享。但是,与、和不同,非常 量和变量 _ 不会 _ 在阶段之间共享。 in``out``const``in``out``uniforms``const
关于顶点着色器性能
这些教程很简单,运行速度应该足够快,但了解各种操作对性能的影响仍然很重要。在本教程中,我们介绍了 3 种移动顶点数据的方法:在 CPU 上自行转换并将其上传到缓冲区对象、在 CPU 上生成转换参数并让顶点着色器使用它们进行转换,以及将尽可能多的数据放在顶点着色器中,只让 CPU 提供最基本的参数。哪种方法最好用?
这个问题很难回答。然而,几乎总是 CPU 转换比 GPU 转换慢。唯一不会慢的情况是,如果你需要在同一帧内多次执行完全相同的转换。即便如此,最好在 GPU 上执行一次转换,并将结果保存在稍后将从中提取的缓冲区对象中。这称为转换反馈,将在后面的教程中介绍。
至于其他两种方法哪种更好,实际上取决于具体情况。以我们的例子为例。在一种情况下,我们在 CPU 上计算偏移量并将其传递给 GPU。GPU 将偏移量应用于每个顶点位置。在另一种情况下,我们仅提供一个时间参数,并且对于每个顶点,GPU 必须计算 _ 完全相同的 _ 偏移量。这意味着顶点着色器正在做大量工作,而所有工作的结果都是相同的数字。
即便如此,这并不意味着它总是更慢。重要的是更改数据的开销。更改统一需要时间;更改矢量统一通常不会比更改单个浮点数花费更多时间,这是因为许多卡处理浮点数学的方式。问题是:在顶点着色器中执行更复杂的操作的成本与需要执行这些操作的频率相比如何。
我们使用的第二个顶点着色器(即计算偏移量的顶点着色器)会进行大量复杂的数学运算。正弦和余弦值的计算速度不是特别快。它们需要进行大量计算才能计算出来。而且由于偏移量本身在单个渲染调用中不会因每个顶点而改变,因此从性能角度来看,最好在 CPU 上计算偏移量并将偏移量作为统一值传递。
通常,这就是大部分渲染的完成方式。顶点着色器被赋予在 CPU 上预先计算的变换值。但这并不意味着这是唯一或最好的方法。在某些情况下,通过传递给顶点着色器的参数化值来计算偏移量通常很有用。
当顶点着色器输入被抽象出来时,这是最好的选择。也就是说,用户不是传递位置,而是传递更一般的信息,着色器会在特定时间或其他参数生成位置。这可以用于基于力的粒子系统;顶点着色器根据时间执行力函数,因此能够计算粒子在任意时间的位置。
我们也看到了这一点。通过将高级信息传递给着色器并让其进行复杂的数学运算,您可以影响的远不止简单的偏移。如果只使用偏移,片段着色器中的色彩动画将无法实现。高级参数化为着色器提供了很大的自由度。
回顾
在本教程中,您学习了以下内容:
-
可以使用该函数部分更新缓冲区对象内容
glBufferSubData。此函数执行的操作相当于一个memcpy操作。 -
着色器中的统一变量是由 GLSL 之外的代码设置的变量。它们仅在渲染调用之间发生变化,因此它们在任何特定三角形的表面上都是统一的。
-
统一变量值与程序对象一起存储。此状态将保留,直到明确更改为止。
-
在两个 GLSL 阶段中定义的具有相同名称和类型的统一变量被视为同一统一变量。在程序对象中设置此统一变量将更改其在两个阶段的值。
进一步研究
您可以测试几件事来查看这些教程的进展情况。
-
使用
VertCalcOffset.cpp,将其更改为绘制两个三角形以圆圈移动,其中一个三角形loopDuration比另一个三角形领先半个。只需在调用后更改制服glDrawArrays,然后glDrawArrays再次调用。在第二次设置之前,将循环持续时间的一半添加到时间中。 -
在 中
FragChangeColor.cpp,将其更改为片段程序在firstColor和 之间跳转secondColor,而不是secondColor在循环结束时从后弹出到第一个。从第一个到第二个再到第一个的转换应该全部发生在一个fragLoopDuration时间间隔内。如果您想知道,GLSL 支持if语句以及 ?: 运算符。但是,为了获得加分,请在没有显式条件语句的情况下执行此操作;请随意使用 sin 或 cos 函数来执行此操作。 -
利用我们对制服的了解,回到 教程 2 的 FragPosition 教程。修改代码,使其采用描述窗口高度的制服,而不是使用硬编码值。更改函数
reshape以绑定程序并使用新高度修改制服。
值得注意的 OpenGL 函数
glBufferSubData
此函数将内存从用户的内存地址复制到缓冲区对象中。此函数将缓冲区对象的字节偏移量作为开始复制的参数,以及要复制的字节数。
当此函数将控制权返回给用户时,您可以立即释放您拥有的内存。因此,您可以分配并填充一块内存,调用此函数,然后立即释放该内存,而不会产生任何危险的副作用。OpenGL 不会存储指针或在以后使用它。
gl 获取统一位置
此函数从给定的程序对象中检索给定名称的统一位置。如果该统一不存在或未被 GLSL 考虑使用,则此函数返回 -1,这不是有效的统一位置。
glUniform*
将当前正在使用的程序中的给定统一 (由 设置 glUseProgram) 设置为给定值。这不仅仅是一个函数,而是一整套采用不同类型的函数。
值得注意的 GLSL 函数
vec **mod**( | 向量分子, |
浮点分母 ); |
该 mod 函数将 的模数除以 numerator。denominator 模数可以被认为是一种引起循环的方式;返回值将以 denominator 循环方式在 [0, ) 范围内。从数学上讲,它定义为 numerator- ( denominator* FLOOR( numerator/ denominator)),其中 FLOOR 将浮点值向下舍入为最小整数。
类型 vec 可以是浮点型或任何向量类型。它必须对所有参数都为同一类型。如果使用向量分母,则对每个相应分量取模数。该函数返回与其 numerator 类型大小相同的向量。
vec **cos**( vec cos( | 矢量角 ); |
vec **sin**( vec sin( | 矢量角 ); |
分别返回给定的 的三角 余弦或正弦angle.,以弧度 angle 为单位。如果 angle 是向量,则返回的向量将具有相同的大小,并且将是 angle 向量每个分量的余弦或正弦。
词汇表
制服
这是一类可以在 GLSL 着色器中定义的全局变量。它们表示在渲染操作过程中保持一致(不变)的值。它们的值是从着色器外部设置的,并且不能从着色器内部更改。
第 4 章 静止物体
到目前为止,我们看到的都是非常扁平的东西。也就是说,只有一个三角形。也许这个三角形会移动,或者有一些颜色。
本教程主要讲述如何创建一个真实的物体世界。
虚幻的世界
正交立方体教程渲染了一个长方体(3D 矩形)。棱柱的尺寸为 0.5x0.5x1.5,因此其 Z 轴长度是 X 和 Y 轴长度的 3 倍。
本教程中的代码大部分内容应该很熟悉。我们只绘制 12 个三角形,而不是 1 个。棱柱的矩形面由 2 个三角形组成,沿其中一条对角线将面分割开。
顶点也有颜色。但是,组成一个面的 6 个顶点的颜色始终相同;这使得每个面都有单一、均匀的颜色。
顶点着色器是我们熟知的一些东西的组合。它将颜色传递到片段阶段,但它也采用 vec2 偏移量统一函数,将偏移量添加到位置的 X 和 Y 分量。片段着色器只是采用插值颜色并将其用作输出颜色。
面剔除
然而,有一个非常值得注意的代码变化:初始化例程。它有几个需要讨论的新功能。
例 4.1. 面剔除初始化
void init()
{
InitializeProgram();
InitializeVertexBuffer();
glGenVertexArrays(1, &vao);
glBindVertexArray(vao);
glEnable(GL_CULL_FACE);
glCullFace(GL_BACK);
glFrontFace(GL_CW);
}最后三行是新的。
该 glEnable 函数是一个多用途工具。有许多二进制开/关标志是 OpenGL 状态的一部分。 glEnable 用于将这些标志设置为 “开”位置。同样,有一个 glDisable 函数可以将标志设置为“关” 。
启用该 GL_CULL_FACE 标志后,将告知 OpenGL 激活 面剔除。到目前为止,我们一直在关闭面剔除的情况下进行渲染。
面剔除是一项节省性能的有用功能。以我们的长方体为例。拿起一个遥控器;它们的一般形状是长方体。无论你如何看它或如何定位它,你一次都看不到它的 3 个以上的面。那么为什么要花费所有的片段处理时间来绘制其他三个面呢?
面剔除是一种告诉 OpenGL 不要绘制您看不到的物体侧面的方法。其实它很简单。
在窗口空间中,从规范化设备坐标转换后,您将得到一个三角形。该三角形的每个顶点都以特定顺序呈现给 OpenGL。这为您提供了一种对三角形顶点进行编号的方法。
无论三角形的大小或形状如何,您都可以将三角形的顺序分为两种:顺时针或逆时针。也就是说,如果顶点从 1 到 2 再到 3 的顺序相对于三角形的中心顺时针旋转一圈,则三角形相对于观察者而言是顺时针方向。否则,三角形相对于观察者而言是逆时针方向。这种顺序称为缠绕顺序 。
图 4.1. 三角形缠绕顺序

左边的三角形按顺时针方向缠绕,右边的三角形按逆时针方向缠绕。
OpenGL 中的面剔除就是基于此顺序进行的。设置此顺序分为两步,由初始化函数的最后两个语句完成。
定义 glFrontFace 哪种缠绕顺序(顺时针或逆时针)被视为三角形的“前”侧。此函数可以给出 GL_CW 或 GL_CCW,分别表示顺时针和逆时针。
该 glCullFace 函数定义哪一侧(正面还是背面)被剔除。这可以给出 GL_BACK、 GL_FRONT 或 GL_FRONT_AND_BACK。后者会剔除 _ 所有内容,_ 因此不会渲染任何三角形。这对于测量顶点着色器性能很有用,但对于实际绘制任何东西都不太有用。
本教程中的三角形数据经过特殊排序,使得三角形的顺时针方向朝外。这可以防止绘制朝后的面。
缺乏远见
因此,图像看起来是这样的:
图 4.2. 正交棱柱

这个有点问题。也就是说,它看起来像一个正方形。
再次拿起遥控器。将其直接对准眼睛,并放置在视线中央。您应该只能看到遥控器的前面板。
现在,将其向右向上移动,类似于正方形的位置。您应该能够看到遥控器的底部和左侧。
所以我们应该能够看到长方体的底部和左侧。但是我们看不到。为什么呢?
回想一下渲染是如何发生的。在裁剪空间中,长方体后端的顶点直接位于前端的后面。当我们将它们转换为窗口坐标时,后顶点仍然直接位于前顶点的后面。这是光栅化器看到的,所以这就是光栅化器渲染的。
现实中一定存在着某些我们没有做到的事情。这些事情被称为“视角” 。
透视投影
回想一下,我们的目标图像,即屏幕,只是一个二维像素数组。我们使用的 3D 渲染管道定义了从剪辑空间到窗口空间的顶点位置的变换。一旦位置进入窗口空间,就会渲染 2D 三角形。
_ 就渲染管道而言,投影 _ 是一种将世界从一个维度转换到另一个维度的方法。我们的初始世界是三维的,因此,渲染管道定义了从这个 3D 世界到我们所见的 2D 世界的投影。三角形实际上是在 2D 世界中渲染的。
我们感兴趣的是有限投影,它只将物体投影到较低维度的有限空间中。对于 3D 到 2D 的投影,有一个有限的平面,世界被投影到该平面上。对于 2D 到 1D,投影的结果是一个有界线。
_ 正交投影 _ 是一种非常简单的投影。当投影到轴对齐的表面上时(如下图所示),投影只需丢弃垂直于表面的坐标即可。
图 4.3. 2D 到 1D 正交投影

正交投影到黑线上的场景。灰色框表示投影中可见的世界部分;该区域之外的场景部分则不可见。
当投影到任意线上时,数学会稍微复杂一些。但正交投影的原理是,垂直于表面的尺寸被均匀地否定以创建投影。它是垂直方向的投影,并且是均匀的,这就是它成为正交投影的原因。
人眼无法通过正交投影看到世界。如果是这样,你只能看到与你的瞳孔大小相当的世界区域。由于我们不使用正交投影来观察(还有其他原因),所以正交投影对我们来说看起来并不特别真实。
相反,我们使用针孔相机模型来观察我们的视力。该模型执行 透视投影。透视投影是将世界投影到表面上,就像通过单个点看到的一样。2D 到 1D 的透视投影如下所示:
图 4.4. 2D 到 1D 透视投影

如您所见,投影是径向的,基于特定点的位置。该点是投影的眼睛或相机。
仅从投影的形状来看,我们可以看出透视投影会将更大的几何区域投影到表面上。正交投影仅捕获投影表面正前方的长方体。透视投影可以捕获更大的世界空间。
在 2D 中,透视投影的形状是正梯形(只有一对平行边,另一对边具有相同斜率的四边形)。在 3D 中,这种形状称为截 _ 头体 _;本质上是一个尖端被切掉的金字塔。
图 4.5. 视锥体

数学视角
既然我们知道我们想要做什么,我们只需要知道如何去做。
我们将做一些简化的假设:
-
投影平面与轴对齐,并朝向 -Z 轴。因此,-Z 距离投影平面较远。
-
视点固定在原点 (0, 0, 0)。
-
投影平面的大小为 [-1, 1]。投影在此范围之外的所有点都不会被绘制。
是的,这听起来有点像规范化的设备坐标空间。不,这不是巧合。但我们不要操之过急。
我们对投影结果的工作原理了解一些。透视投影本质上是根据特定顶点的位置将顶点移向眼睛。在 Z 方向上距离投影前方较远的顶点的偏移量小于靠近眼睛的顶点。并且偏移量还取决于顶点在 X、Y 方向上距离投影平面中心的距离。
这个问题其实只是一个简单的几何问题。以下是 2D 到 1D 透视投影的等效形式。
图 4.6. 2D 到 1D 透视投影图

点 P 在投影平面上的投影。该平面与固定在原点的视点相比偏移了 E z。R 是投影点。
我们有两个相似的直角三角形:由 E、R 和 Ez 形成的三角形,以及由 E、P 和 Pz 形成的三角形。我们有眼睛的位置和非投影点的位置。要找到 R 的位置,我们只需执行以下操作:
公式 4.1. 透视计算
由于这是一个矢量化函数,因此该解决方案同样适用于 2D 和 3D。因此,透视投影只是将这个简单公式应用于顶点着色器接收到的每个顶点的任务。
观点分歧
基本透视投影函数很简单。真的很简单。事实上,它非常简单,从最早的 3Dfx 卡甚至更早的图形硬件时代起,它就被内置到图形硬件中。
您可能会注意到,缩放可以表示为除法运算(乘以倒数)。您可能还记得,剪辑空间和规范化设备坐标空间之间的差异是除以 W 坐标。因此,我们可以简单地正确设置每个顶点的 W 坐标并让硬件处理它,而不是在着色器中进行除法。
这一步,即从裁剪空间到规范化设备坐标空间的转换,有一个特定的名字:透视除法。之所以这样命名,是因为它通常用于透视投影;正交投影的 W 坐标往往为 1.0,因此透视除法是一个无操作。
Note
您可能想知道为什么存在这种任意的按 W 除法步骤。您可能还想知道,在当今这个可以非常快速地进行矢量除法的顶点着色器时代,我们为什么要费心使用硬件按 W 除法步骤呢?有几个原因。其中一个原因我们将在处理矩阵时稍微介绍一下。更重要的原因将在以后的教程中介绍。可以说,将透视项放在裁剪空间顶点的 W 坐标中是有充分理由的。
相机视角
在实际实现透视投影之前,我们需要处理一个新问题。正交投影变换本质上是无操作的。它是自动的,这是由 OpenGL 使用顶点着色器输出的剪辑空间顶点的性质决定的。透视投影变换稍微复杂一些。事实上,它从根本上改变了世界的本质。
此前,我们的顶点位置已直接存储在裁剪空间中。我们有时会为位置添加偏移量,以将它们移动到更方便的位置。但无论出于何种目的,存储在缓冲区对象中的位置值都正是我们的顶点着色器输出的内容:裁剪空间位置。
回想一下,除以 W 是 OpenGL 定义的从裁剪空间位置到 NDC 位置的变换的一部分。透视投影定义了将位置变换 _ 到 _ 裁剪空间的过程,这样这些裁剪空间位置看起来就像是 3D 世界的透视投影。这种变换具有明确定义的输出:裁剪空间位置。但它的 _ 输入 _ 值到底是什么?
因此,我们为位置定义了一个新的空间;我们称这个空间为 相机空间。3(https://paroj.github.io/gltut/Positioning/Tut04%20Perspective%20Projection.html#ftn.idp2545) 这不是 OpenGL 识别的空间(与 GL 明确定义的裁剪空间不同);它纯粹是用户的任意构造。相机空间的定义将影响透视投影的确切过程,因为该投影必须产生适当的裁剪空间位置。因此,根据我们对透视投影的一般过程的了解来定义相机空间会很有用。这最大限度地减少了相机空间和裁剪空间的透视形式之间的差异,并且可以简化我们的透视投影逻辑。
相机空间的体积在所有方向上都在正无穷到负无穷之间变化。正 X 向右延伸,正 Y 向上延伸,正 Z_ 向前 _。最后一个与剪辑空间不同,正 Z 向外延伸。
我们的透视投影变换将特定于此空间。如前所述,投影平面应为 X 和 Y 轴上的 [-1, 1] 区域,Z 值为 -1。投影将从 -Z 方向的顶点到此平面;具有正 Z 值的顶点位于投影平面后面。
现在,我们再做一个简化的假设:透视平面中心的位置在相机空间中固定在 (0, 0, -1)。因此,由于投影平面指向 -Z 轴,眼睛相对于投影平面的位置为 (0, 0, -1)。因此,E z 值(从投影平面到眼睛的偏移量)始终为 -1。这意味着我们的透视术语,当用除法而不是乘法来表达时,就是 P z /-1:相机空间 Z 坐标的负数。
固定的眼点位置和投影平面使得很难实现放大/缩小式的效果。这通常是通过相对于固定的眼点移动平面来实现的。但是,有一种方法可以做到这一点。您需要做的就是,当从相机空间转换到剪辑空间时,将所有 X 和 Y 值缩放一个常数。这样做会使相机看到的世界在 X 轴和 Y 轴上变小或变大。它有效地使视锥体变宽或变窄。
为了进行比较,相机空间和标准化设备坐标空间(透视除法之后)如下所示,使用 2D 版本的透视投影:
图 4.7. 相机到 NDC 的 2D 变换

请注意,此图的 Z 轴与相机空间和标准化设备坐标 (NDC) 空间的 Z 轴是翻转的。这是因为相机空间和 NDC 空间的观察方向不同。在相机空间中,相机向下看 -Z 轴;Z 值越负,距离越远。在 NDC 空间中,相机向下看 +Z 轴;Z 值越正,距离越远。此图翻转了轴,以便观察方向在两个图像之间可以保持不变(向上为远离)。
如果你在右侧的 NDC 空间中执行正交投影(通过删除 Z 坐标),那么左侧得到的是世界的透视投影。实际上,我们所做的就是将对象转换为三维空间,从这个三维空间中,正交投影看起来就像透视投影。
深度透视
现在我们知道了如何处理 X 和 Y 坐标。但是在透视投影中 Z 值是什么意思呢?
在下一节教程之前,我们将忽略 Z 的 _ 含义 _ 。即便如此,我们仍然需要对其进行某种变换;如果顶点在规范化设备坐标 (NDC) 空间中的任何轴上延伸到 [-1, 1] 框之外,则它位于可视区域之外。而且由于 Z 坐标与 X 和 Y 坐标一样经过透视除法,因此如果我们真的想在投影中看到任何东西,就需要考虑到这一点。
我们的 W 坐标将基于相机空间 Z 坐标。我们需要将 Z 值从相机空间范围 [0, -∞) 映射到 NDC 空间范围 [-1, 1]。由于相机空间是无限范围,而我们试图映射到有限范围,因此我们需要进行一些范围限制。视锥体在 X 和 Y 方向上已经有限限制;我们只需添加 Z 边界即可。
顶点在被认为不再在视野范围内之前的最大距离是 _ 相机 zFar_。我们与眼睛还有一个最小距离;这称为 _ 相机 zNear_。这为我们的相机空间视点创建了一个有限的视锥体。
Note
记住这些是 _ 相机 _ 空间的 zNear 和 zFar 非常重要。下一个教程还将介绍深度范围,也使用名称 zNear 和 zFar。这是一个相关但根本不同的范围。
相机 zNear 似乎可以有效地确定眼睛和投影平面之间的偏移。然而,事实并非如此。即使 zNear 小于 1,这会将近 Z 平面置于投影平面 _ 后面 _,您仍然可以获得有效的投影。平面后面的物体可以像平面前面的物体一样投影到平面上;它仍然是透视投影。从数学上讲,这是可行的。
如果您移动投影平面,它不会 _ 执行 _ 您所期望的操作。由于投影平面具有固定大小(范围 [-1, 1]),因此移动平面会改变投影中点出现的位置。更改相机 zNear 不会影响投影中点的 X、Y 位置。
有几种方法可以将一个有限范围映射到另一个有限范围。一个令人困惑的问题是透视除法本身;在两个有限空间之间进行线性映射很容易。但 _ 在 _ 透视除法之后进行保持线性的映射则完全是另一回事。由于我们将除以 -Z 本身(相机空间 Z,而不是剪辑空间 Z),因此数学运算比您想象的要复杂得多。
出于将在下一个教程中更好地解释的原因,我们将使用这个适度复杂的函数来计算裁剪空间 Z:
公式 4.2. 深度计算

关于这个方程和相机 zNear/zFar 的一些重要事项。首先,这些值是 _ 正数 ;方程在执行变换时会考虑到这一点。此外,zNear 不能 _ 为 0;它可以非常接近零,但绝不能正好为零。
我们来回顾一下前面二维空间中相机到 NDC 变换的示意图:
2D 相机空间与 2D NDC 空间的示例使用此方程来计算 Z 值。仔细看看 Z 坐标如何匹配。Z 距离在相机空间中均匀分布,但在 NDC 空间中,它们是非线性分布的。但同时,在相机空间中共线的点在 NDC 空间中仍然共线。
这个事实有一些有趣的特性,我们将在下一个教程中进一步研究。
透视绘画
考虑到以上所有情况,我们现在有了将顶点从相机空间转换为裁剪空间的特定步骤序列。这些步骤如下:
-
视锥调整:将相机空间顶点的 X 和 Y 值乘以一个常数。
-
深度调整:修改从相机空间到剪辑空间的 Z 值,如上。
-
透视除法项:计算 W 值,其中 E z 为 -1。
现在我们已经掌握了所有理论,可以开始正确地看待事物了。这是在 ShaderPerspective 教程中完成的。
我们的新顶点着色器 data\ManualPerspective.vert 如下所示:
例 4.2. ManualPerspective 顶点着色器
#version 330
layout(location = 0) in vec4 position;
layout(location = 1) in vec4 color;
smooth out vec4 theColor;
uniform vec2 offset;
uniform float zNear;
uniform float zFar;
uniform float frustumScale;
void main()
{
vec4 cameraPos = position + vec4(offset.x, offset.y, 0.0, 0.0);
vec4 clipPos;
clipPos.xy = cameraPos.xy * frustumScale;
clipPos.z = cameraPos.z * (zNear + zFar) / (zNear - zFar);
clipPos.z += 2 * zNear * zFar / (zNear - zFar);
clipPos.w = -cameraPos.z;
gl_Position = clipPos;
theColor = color;
}
我们有几套新制服,但制服规范本身并不太复杂。
第一条语句只是应用了偏移,就像我们之前见过的顶点着色器一样。它将对象定位在相机空间中,以便它偏离视图的中心。这样做是为了更容易定位对象以进行投影。
下一个语句对相机空间 X 和 Y 位置进行标量乘法,并将它们存储在临时的 4 维向量中。然后,我们根据前面讨论的公式计算剪辑 Z 位置。
剪辑空间位置的 W 坐标是相机空间中的 Z 距离除以平面(原点)到眼睛的 Z 距离。眼睛固定在 (0, 0, -1),因此这留给我们相机空间 Z 位置的负数。OpenGL 会自动为我们执行除法。
之后,我们只需将裁剪空间位置存储在 OpenGL 需要的位置,存储颜色,就大功告成了。片段着色器保持不变。
随着所有新制服的出现,我们的程序初始化例程已经发生了变化:
例 4.3. 程序初始化
offsetUniform = glGetUniformLocation(theProgram, "offset");
frustumScaleUnif = glGetUniformLocation(theProgram, "frustumScale");
zNearUnif = glGetUniformLocation(theProgram, "zNear");
zFarUnif = glGetUniformLocation(theProgram, "zFar");
glUseProgram(theProgram);
glUniform1f(frustumScaleUnif, 1.0f);
glUniform1f(zNearUnif, 1.0f);
glUniform1f(zFarUnif, 3.0f);
glUseProgram(0);我们只设置一次新的制服。1.0 的比例实际上意味着没有变化。我们将 Z 定义为从 -1 到 -3(请记住,在我们的 Z 方程中,zNear 和 zFar 是正数,但指的是负值)。
棱镜的位置也发生了变化。在原始教程中,它位于 Z 轴的 0.75 范围内。由于相机空间与剪辑空间的 Z 轴非常不同,因此必须进行更改。现在,棱镜的 Z 轴位置在 -1.25 和 -2.75 之间。
所有这些给我们留下了这样的结果:
图 4.8. 透视棱镜

现在,它看上去就像一个长方体,明亮、多彩,却又不切实际。
矢量数学
我们略过了顶点着色器中值得进一步讨论的内容。即这一行:
clipPos.xy = cameraPos.xy * frustumScale;
即使您熟悉其他语言中的向量数学库,此代码也应该相当奇怪。传统的向量库允许您编写选择器,如 vec.x 和,vec.w 以便从向量中获取特定字段。那么像什么意思呢 vec.xy ?
嗯,很明显;这个表达式返回一个 2D 向量 ( vec2 ),因为只提到了两个分量 (X 和 Y)。这个向量的第一个分量来自 的 X 分量 vec,第二个分量来自 的 Y 分量 vec。这种选择在 GLSL 术语中称为 _ 混合选择。_ 返回向量的大小将是您提到的分量数,这些分量的顺序将决定返回分量的顺序。
你可以对向量执行任何类型的混合操作,只要你牢记以下规则:
-
您不能选择不在源向量中的组件。因此,如果您有:
vec2 theVec; vec2theVec;
您无法做到这一点,
theVec.zz因为它没有 Z 组件。 -
您不能选择超过 4 个组件。
这些是唯一的规则。因此,您可以拥有一个 vec2,然后对其进行混合以创建 vec4 ( vec.yyyx);您可以重复组件;等等。只要您遵守这些规则,一切皆有可能。
您还应该假设 swizzling 速度很快。对于大多数基于 CPU 的矢量硬件来说,情况并非如此,但自可编程 GPU 诞生之初,swizzle 选择就一直是一个突出的功能。在可编程的早期,swizzle _ 不会 _ 导致性能损失;很可能,这种情况没有改变。
混合选择也可以用在等号的左侧,就像我们在这里做的一样。它允许你设置矢量的特定分量而不改变其他分量。
当你将一个向量乘以一个标量(非向量值)时,它会进行逐个分量的乘法,返回一个向量,该向量包含标量与向量的每个分量的乘积。我们可以将上面的代码写成如下形式:
ClipPos.x =cameraPos.x * frustumScale; ClipPos.y =cameraPos.y * frustumScale; ClipPos.x =cameraPos.x * 视锥体比例;ClipPos.y =cameraPos.y * 视锥体比例;
但它可能不如混合和矢量数学版本那么快。
矩阵
所以,既然我们已经能够正确看待这个世界,那就让我们用正确的方式去做吧。 “暂时没有必要太复杂,但经过一些教程就会明白”的方式。
首先,让我们看一下用于从相机空间计算裁剪坐标的方程组。假设 S 是视锥体比例因子, N 是 zNear,F 是 zFar,我们得到以下四个方程。
公式 4.3. 相机到剪辑的公式

奇怪的间距是故意的。为了搞笑,我们添加一些无意义的术语,它们不会改变方程式,但会开始形成一个有趣的模式:
方程 4.4. 相机到剪辑扩展方程

这里我们得到的是所谓的线性方程组。方程可以指定为一系列系数(乘以 XYZW 值的数字),这些系数与输入值(XYZW)相乘以产生单个输出。每个单独的输出值都是所有输入值的线性组合。在我们的例子中,恰好有很多零系数,因此这种特定情况下的输出值仅取决于少数输入值。
您可能想知道 Z clip 值的加法项与相机空间 W 的乘积。好吧,我们输入的相机空间位置的 W 坐标始终为 1。因此,只要情况仍然如此,执行乘法就是有效的。能够执行我们即将执行的操作是 W 坐标存在于我们的相机空间位置值中的部分原因(另一个原因是透视除法)。
我们可以用一种特殊的公式重新表达任何线性方程组。根据你对线性代数的了解,你可能会认出这种公式:
公式 4.5. 相机到剪辑矩阵的转换

XYZW 的两个长垂直列标记为“剪辑”和 “相机”,是 4 维向量;即剪辑和相机空间位置向量。较大的数字块是一个矩阵。您可能不熟悉矩阵数学。如果不熟悉,稍后会进行解释。
一般而言,_ 矩阵 _ 是二维数字块(超过 2 维的矩阵称为“张量”)。矩阵在计算机图形学中非常常见。到目前为止,我们能够不用它们。然而,随着我们进入更详细的对象转换,我们将越来越多地依赖矩阵来简化问题。
在图形工作中,我们通常使用 4x4 矩阵;即分别具有 4 列和 4 行的矩阵。这是由于图形工作的性质:我们想要使用矩阵的大多数东西都是 3 维的,或者是带有额外数据坐标的 3 维。我们的 4D 位置只是在末尾添加了 1 的 3D 位置。
上面描述的操作是向量与矩阵相乘。维度为 nx 的矩阵 m 只能与维度为 的向量相乘 n。这种乘法的结果是一个维度为 的向量 m。由于本例中的矩阵是 4x4,因此它只能与 4D 向量相乘,并且此乘法将产生一个 4D 向量。
矩阵乘法的作用与扩展方程示例相同。对于矩阵中的每一行,列中每个分量的值都会与向量行中的相应值相乘。然后,将这些值相加;这将成为输出向量行的单个值。
等式 4.6. 向量矩阵乘法
这最终导致执行 16 次浮点乘法和 12 次浮点加法。这相当多,特别是与我们当前的版本相比。幸运的是,图形硬件旨在使这些操作非常快。由于每个乘法彼此独立,因此它们可以同时完成,这正是图形硬件快速完成的事情。同样,加法运算是部分独立的;每行的总和不依赖于任何其他行的值。最终,向量矩阵乘法通常只生成 GPU 机器语言中的 4 条指令。
我们可以使用矩阵数学而不是显式数学来重新实现上述透视投影。MatrixPerspective 教程就是这样做的。
在这种情况下,顶点着色器要简单得多:
例 4.4. MatrixPerspective 顶点着色器
#version 330
layout(location = 0) in vec4 position;
layout(location = 1) in vec4 color;
smooth out vec4 theColor;
uniform vec2 offset;
uniform mat4 perspectiveMatrix;
void main()
{
vec4 cameraPos = position + vec4(offset.x, offset.y, 0.0, 0.0);
gl_Position = perspectiveMatrix * cameraPos;
theColor = color;
}
OpenGL 着色语言 (GLSL) 专为图形操作而设计,自然具有矩阵作为基本类型。mat4 是一个 4x4 矩阵(列 x 行)。 GLSL 具有 2 到 4 之间的所有列和行组合的类型。方阵(列数和行数相等的矩阵)仅使用一个数字,如 上面的 mat4。因此 mat3 是一个 3x3 矩阵。如果矩阵不是方阵,GLSL 使用类似 mat2x4 的符号:具有 2 列和 4 行的矩阵。
请注意,着色器不再自行计算值;它会 _ 被赋予 _ 一个矩阵,其中包含所有存储的值作为统一值。这只是因为没有必要。特定场景中的所有对象都将使用相同的透视矩阵进行渲染,因此无需浪费可能宝贵的顶点着色器时间进行冗余计算。
向量矩阵乘法是图形学中很常见的操作,因此使用运算符 * 来执行该操作。因此,第二行将 main 透视矩阵乘以相机位置。
请注意此操作的 _ 顺序 _。矩阵在左边,向量在右边。矩阵乘法 _ 不 _ 具有交换性,因此 Mv 与 vM 不同。通常,向量被视为 1xN 矩阵(其中 N 是向量的大小)。当您在矩阵左侧乘以向量时,GLSL 会将其视为 Nx1 矩阵;这是使乘法有意义的唯一方法。这会将向量的单行与每一列相乘,将结果相加,创建一个新向量。这不是 _ 我们 _ 想要做的。我们希望将矩阵的行乘以向量,而不是矩阵的列。将向量放在右侧,而不是左侧。
程序初始化例程有一些变化:
例 4.5. 透视矩阵的程序初始化
offsetUniform = glGetUniformLocation(theProgram, "offset");
perspectiveMatrixUnif = glGetUniformLocation(theProgram, "perspectiveMatrix");
float fFrustumScale = 1.0f; float fzNear = 0.5f; float fzFar = 3.0f;
float theMatrix[16];
memset(theMatrix, 0, sizeof(float) * 16);
theMatrix[0] = fFrustumScale;
theMatrix[5] = fFrustumScale;
theMatrix[10] = (fzFar + fzNear) / (fzNear - fzFar);
theMatrix[14] = (2 * fzFar * fzNear) / (fzNear - fzFar);
theMatrix[11] = -1.0f;
glUseProgram(theProgram);
glUniformMatrix4fv(perspectiveMatrixUnif, 1, GL_FALSE, theMatrix);
glUseProgram(0);4x4 矩阵包含 16 个值。因此,我们首先创建一个名为 的 16 个浮点数数组 theMatrix。由于大多数值都是零,我们可以将整个数组设置为零。这是可行的,因为 IEEE 32 位浮点数将零表示为 4 个字节,且所有字节都包含零。
接下来的几个函数将感兴趣的特定值设置到矩阵中。在理解这里发生的事情之前,我们需要先讨论一下排序。
从技术上讲,4x4 矩阵有 16 个值,因此 16 项数组可以存储矩阵。但有两种方法可以将矩阵存储为数组。一种方法称为 _ 列主 _ 序,另一种自然是 _ 行主 _ 序。列主序意味着,对于 NxM 矩阵(列 x 行),数组中的前 N 个值是第一列(从上到下),接下来的 N 个值是第二列,依此类推。在行主序中,数组中的前 M 个值是第一行(从左到右),后面是第二行的另外 M 个值,依此类推。
在此示例中,矩阵按列优先顺序存储。因此数组索引 14 位于第三行第四列。
整个矩阵是一个统一的矩阵。要将矩阵传输到 OpenGL,我们使用函数 glUniformMatrix4fv。第一个参数是我们要上传到的统一位置。此函数可用于传输整个矩阵数组(是的,任何类型的统一数组都是可能的),因此第二个参数是数组条目的数量。由于我们只提供一个矩阵,因此该值为 1。
第三个参数告诉 OpenGL 矩阵数据的顺序。如果是 GL_TRUE,则矩阵数据按行优先顺序排列。由于我们的数据是按列优先顺序排列,因此我们将其设置为 GL_FALSE。最后一个参数是矩阵数据本身。
运行这个程序将会给我们:
图 4.9. 透视矩阵

和我们之前做过的一样。只不过现在用矩阵来完成。
世界的面貌
如果您运行最后一个程序并调整窗口大小,视口也会随之调整大小。不幸的是,这也意味着原本是方形前部的长方体会变得细长。
图 4.10. 糟糕的长宽比
_ 这是长宽比 _ 的问题,即图像的宽度与高度之比。目前,当您更改窗口的尺寸时,代码会调用 glViewport 以告诉 OpenGL 新的大小。这会改变 OpenGL 的视口变换,即从规范化的设备坐标变为窗口坐标。NDC 空间的长宽比为 1:1;NDC 空间的宽度和高度为 2x2。只要窗口坐标的宽高比也是 1:1,在 NDC 空间中显示为正方形的物体在窗口空间中仍然是正方形。一旦窗口空间变为非 1:1,就会导致变换也变为非正方形。
到底能做些什么呢?这取决于你通过放大窗口想要达到什么目的。
一个简单的方法是防止视口变成非正方形。只需将函数更改 reshape 为以下内容即可轻松完成此操作:
例 4.6. 仅限正方形的视口
void reshape (int w, int h)
{
if(w < h)
glViewport(0, 0, (GLsizei) w, (GLsizei) w);
else
glViewport(0, 0, (GLsizei) h, (GLsizei) h);
}现在,如果您调整窗口大小,视口将始终保持正方形。但是,如果窗口不是正方形,视口区域的右侧或下方将有大量空白空间。这些空间无法使用三角形绘制命令进行渲染(原因我们将在下一个教程中看到)。
此解决方案的优点是无论视口的形状如何,都可以保持世界的可视区域固定。缺点是浪费窗口空间。
如果我们想尽可能多地利用窗户,该怎么办?有一种方法可以做到这一点。
回到问题的定义。NDC 空间是一个 [-1, 1] 立方体。如果 NDC 空间中的对象是正方形,则为了使其在窗口坐标中为正方形,视口也必须是正方形。相反,如果您想要非正方形的窗口坐标,则 NDC 空间中的对象 _ 不能是正方形。_
因此,我们的问题在于隐含的假设,即相机空间中的正方形需要始终保持正方形。事实并非如此。为了实现我们想要的效果,我们需要将物体变换到裁剪空间,使它们成为正确的非正方形形状,一旦透视除法和视口变换将它们转换为窗口坐标,它们就会再次变成正方形。
目前,我们的透视矩阵定义了一个方形的视锥体。也就是说,视锥体的顶部和底部(如果在相机空间中可视化)将是正方形。我们需要做的是创建一个矩形视锥体。
图 4.11。宽屏长宽比平截头体

我们已经对视锥体的形状有了一定的控制。我们最初说过,我们不需要将眼睛位置从原点移开,因为我们只需缩放所有物体的 X 和 Y 位置即可实现类似的效果。当我们这样做时,我们会将 X 和 Y 缩放相同的值;这样会产生均匀的缩放比例。它还会生成一个方形视锥体,就像在相机空间中看到的那样。由于我们想要一个矩形视锥体,因此我们需要使用非均匀缩放,其中 X 和 Y 位置按不同的值缩放。
这样做的目的是展示 _ 更多的 _ 世界。但是我们想在哪个方向展示更多?人类的视觉往往是水平的而不是垂直的。这就是为什么电影倾向于使用至少 16:9 的宽度:高度纵横比(大多数电影使用的宽度都大于这个数字)。所以通常情况下,你会为特定的高度设计一个视图,然后根据纵横比调整宽度。
这是在 AspectRatio 教程中完成的。此代码使用与以前相同的着色器;它只是修改了函数中的透视矩阵 reshape。
例 4.7. 使用纵横比重塑
void reshape (int w, int h)
{
perspectiveMatrix[0] = fFrustumScale / (w / (float)h);
perspectiveMatrix[5] = fFrustumScale;
glUseProgram(theProgram);
glUniformMatrix4fv(perspectiveMatrixUnif, 1, GL_FALSE, perspectiveMatrix);
glUseProgram(0);
glViewport(0, 0, (GLsizei) w, (GLsizei) h);
}矩阵现在是一个全局变量,名为 perspectiveMatrix,它像以前一样从程序初始化函数中获取其他字段。纵横比代码只对 XY 比例值感兴趣。
这里,我们根据宽度和高度的比例来改变 X 轴的缩放比例。Y 轴的缩放比例保持不变。
此外,用于定位棱镜的偏移量已从 (0.5, 0.5) 更改为 (1.5, 0.5)。这意味着,除非您调整窗口大小,否则对象的一部分会偏离视口的一侧。更改宽度会显示更多区域;只有通过更改高度,您才能真正使对象变大。正方形始终看起来像正方形。
回顾
在本教程中,您学习了以下内容:
-
面剔除可能导致三角形根据窗口空间中顶点的顺序被剔除(不被渲染)。
-
透视投影用于为场景提供深度外观,其中较远的物体看起来比近处的物体更小且偏移。OpenGL 硬件对透视投影有特殊规定;即从剪辑空间到 NDC 空间除以 W 的变换。
-
透视变换可以作为矩阵乘法运算来执行。矩阵/向量乘法是一种在单个运算中计算多个线性方程的方法。
-
通过根据窗口的纵横比缩放相机空间顶点的 X 和 Y 坐标,可以保持显示图像的正确纵横比。此变换可以折叠到透视投影矩阵中。
进一步研究
尝试使用给定的程序做这些事情。
-
在所有透视教程中,我们只使用 1.0 的视锥体比例。调整视锥体比例,看看它如何影响场景。
-
调整 zNear 距离,使其与棱镜相交。看看这会如何影响渲染。同样调整 zFar 距离,看看会发生什么。
-
我们在透视变换算法中做了一些简化假设。具体来说,我们将视点固定在 (0, 0, 0),平面固定在 (0, 0, 1)。然而,这并不是绝对必要的;我们可以改变透视变换算法以使用可变的视点。调整 ShaderPerspective 以实现任意透视平面位置(大小保持固定在 [-1, 1])。您需要分别将顶点的 X、Y 相机空间位置偏移 E x 和 E y,但仅 _ 在 _ 缩放之后(针对纵横比)。并且您需要将相机空间 Z 项除以 -E z, 而不仅仅是 -1。
-
执行上述操作,但采用矩阵形式。请记住,由于乘以 W 相机(始终为 1.0),第四列中的任何项都将添加到该组件中。
值得注意的 OpenGL 函数
glEnable/glDisable
这些函数可激活或停用 OpenGL 的某些功能。可以启用或禁用的功能有很多。在本教程中,GL_CULL_FACE 用于启用/禁用面剔除。
glCullFace/glFrontFace
这两个函数控制面剔除的工作方式。 glFrontFace 定义哪个三角形缠绕顺序被视为正面。glCullFace 定义哪些面被剔除。此函数还可以剔除 _ 所有 _ 面,但如果您想完成渲染,这没什么用。
这些函数仅在当前启用时才有用 GL_CULL_FACE。即使未启用,它们仍会在内部设置值 GL_CULL_FACE,因此稍后启用它将使用最新的设置。
词汇表
面剔除
根据三角形的缠绕顺序剔除三角形的能力。此功能在 OpenGL 中通过使用 来激活 glEnable。GL_CULL_FACE 剔除哪些面由 glCullFace 和 glFrontFace 函数决定。
缠绕顺序
组成三角形的 3 个顶点的接收顺序(顺时针或逆时针)。这是以二维窗口坐标来测量的。
投影
将一系列高维对象转换为低维对象。将 3D 场景渲染为 2D 图像需要将该场景从三维投影到二维。
投影总是相对于投影面进行。将二维空间投影到一维空间需要投影到一条有限的线上。将三维空间投影到二维空间需要投影平面。这个表面是在高维世界中定义的。
正交投影
一种投影形式,简单地否定与投影表面垂直的所有偏移。进行 3D 到 2D 正交投影时,如果平面与轴对齐,则投影可以简单完成。垂直于投影平面的坐标将被丢弃。如果平面与轴不对齐,则数学运算更复杂,但效果相同。
正交投影在投影方向上是均匀的。由于均匀性,保证在高维空间中平行的线在低维空间中保持平行。
透视投影
一种基于位置(眼睛位置)投影到表面的投影形式。透视投影试图模拟针孔相机模型,这与人眼的视觉方式类似。空间中物体的位置基于眼睛位置以径向方式投影到投影表面上。
高维空间中的平行线 _ 不一定 _ 在低维空间中也保持平行。它们可能保持平行,也可能不保持平行。
截头体
从几何学上来说,截头锥体是一种 3D 形状;一个顶部被切掉的金字塔。从眼睛到投影平面的 3D 到 2D 透视投影视图具有截头锥体的形状。
观点分歧
这是从剪辑空间到规范化设备坐标空间的转换的新名称。之所以这样称呼,是因为除以 W 后,透视投影就可以仅使用矩阵数学进行工作;否则,矩阵本身无法执行完整的透视投影操作。
相机空间
任意定义但非常有用的空间,从中可以相对轻松地执行透视投影。相机空间是一个无限大的空间,正 X 向右,正 Y 向上,正 Z 朝向观察者。
在相机空间中,透视投影的视线位置假定为 (0, 0, 1),投影平面是 X 和 Y 轴上的 [-1, 1] 平面,该平面通过 3D 原点。因此,所有具有正 Z 的点都被视为位于相机后方,因此不在视野范围内。相机空间中的位置是相对于相机位置定义的,因为相机具有固定的原点。
相机 zNear,相机 zFar
规范化设备坐标 (NDC) 空间在所有维度上都有限制,范围为 [-1, 1]。相机空间没有限制,但透视变换会隐式地将视野范围内的内容限制在 X 轴和 Y 轴的 [-1, 1] 内。这使得 Z 轴没有限制,而这是 NDC 空间所不允许的。
相机 zNear 和 zFar 值是定义透视投影变换中 Z 的最小和最大范围的数字。这些值是正数,但它们在相机空间中表示负值。使用标准透视变换,两个值都必须大于 0,并且 zNear 必须小于 zFar。
调酒选择
Swizzle 选择是一种矢量技术,是着色语言所独有的,它允许您取一个矢量并任意从其组件构建其他矢量。此选择完全是任意的;您可以从 vec2 构建 vec4,或者以您想要的任何其他组合构建,最多 4 个元素。
混合选择使用“ x ” 、 “ y ” 、 “ z ”和“ w ”的组合从输入向量中挑选出分量。混合操作如下所示:
vec2 第一个 Vec; vec4 第二个 Vec = 第一个 Vec.xyxx; vec3 第三个 Vec = 第二个 Vec.wzy;
在图形硬件中,混合选择被认为是一种非常快的操作,可以即时完成。也就是说,图形硬件在构建时就考虑到了混合选择。
矩阵
数字的二维排列。与向量一样,矩阵可以被视为单个元素。矩阵通常用于表示线性方程组中的系数;因此(除其他外),矩阵数学通常被称为线性代数。
矩阵的大小、列数和行数(表示为 NxM,其中 N 是列数,M 是行数)决定了矩阵的类型。矩阵算术对所涉及的两个矩阵有特定要求,具体取决于算术运算。只有当左侧矩阵的行数等于右侧矩阵的列数时,才能将两个矩阵相乘。出于这个原因,矩阵乘法不满足交换律(AB 不是 BA;有时甚至不可能是 B*A)。
4x4 矩阵在计算机图形学中用于将 3 维或 4 维向量从一个空间变换到另一个空间。大多数类型的线性变换都可以用 4x4 矩阵表示。
列主序、行主序
这些术语定义了将矩阵存储为值数组的两种方式。列主序意味着,对于 NxM 矩阵(列 x 行),数组中的前 N 个值是第一列(从上到下),接下来的 N 个值是第二列,依此类推。按行主序,数组中的前 M 个值是第一行(从左到右),后面是第二行的另外 M 个值,依此类推。
第 5 章 对象深度
在本教程中,我们将研究如何处理渲染多个对象,以及多个对象重叠时会发生什么。
OpenGL 中的多个对象
要了解对象重叠时会发生什么情况,第一步是绘制多个对象。这是一个讨论未来有用的概念的机会。
就您绘制的内容而言,对象可以视为单个绘制调用的结果。因此,对象是您使用一组程序对象状态绘制的最小三角形系列。
顶点数组对象
到目前为止,每次我们尝试绘制任何东西时,我们都需要在绘制调用之前进行某些设置工作。具体来说,对于顶点着色器使用的 _ 每个顶点属性,我们必须执行以下操作:_
-
用于
glEnableVertexAttribArray启用该属性。 -
使用
glBindBuffer(GL_ARRAY_BUFFER)将包含此属性数据的缓冲区对象绑定到上下文。 -
用于
glVertexAttribPointer定义先前绑定的缓冲区对象内的属性的数据格式GL_ARRAY_BUFFER。
属性越多,需要为每个对象做的工作就越多。为了减轻这种负担,OpenGL 提供了一个对象来存储渲染所需的所有状态:顶点数组对象 ( VAO )。
VAO 是使用函数创建的 glGenVertexArray。其工作原理 glGenBuffers 与大多数其他 OpenGL 对象类似;您可以通过一次调用创建多个对象。与之前一样,对象是 GLuint。
VAO 通过 绑定到上下文 glBindVertexArray;此函数不像 那样接受目标 glBindBuffer。它仅接受 VAO 来绑定到上下文。
一旦 VAO 被绑定,对某些函数的调用就会改变绑定 VAO 中的数据。从技术上讲,它们 _ 总是 _ 会改变 VAO 的状态;所有之前的教程都在初始化函数中写了这些代码:
glGenVertexArrays(1,&vao); glBindVertexArray(vao);
这将创建一个 VAO,其中包含我们一直在设置的顶点数组状态。这意味着我们在所有教程中都在更改 VAO 的状态。我们只是当时没有谈论它。
以下函数会更改 VAO 状态。因此,如果没有 VAO 绑定到上下文(如果您调用 glBindVertexArray(0) 或根本没有绑定 VAO),则所有这些函数(除非另有说明)都将失败。
-
glVertexAttribPointer。还有glVertexAttribIPointer,但我们还没有谈论这个。 -
glEnableVertexAttribArray/glDisableVertexAttribArray -
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER):在没有 VAO 绑定的情况下调用此项不会失败。
缓冲区绑定和属性关联
您可能会注意到 glBindBuffer( GL_ARRAY_BUFFER) 不在该列表中,即使它是渲染属性设置的一部分。绑定到 GL_ARRAY_BUFFER 不是 VAO 的一部分,因为 当您调用 ( ) 时,缓冲区对象和顶点属性之间的关联 _ 不会 _ 发生。当您调用 时,会发生这种关联 。glBindBuffer``GL_ARRAY_BUFFER``glVertexAttribPointer
当您调用 时,OpenGL 会获取 _ 此调用时 _ 绑定到 的 glVertexAttribPointer 任何缓冲区,并将其与给定的顶点属性关联。将绑定视为读取的全局指针。因此,_ 在调用后,_ 您可以自由地绑定任何内容或不绑定任何内容 ;这不会对最终渲染产生 _ 任何 _ 影响。因此,VAO 会存储哪些缓冲区对象与哪些属性相关联;但它们不会存储绑定本身。GL_ARRAY_BUFFER``GL_ARRAY_BUFFER``glVertexAttribPointer``GL_ARRAY_BUFFER glVertexAttribPointer``GL_ARRAY_BUFFER
如果您想知道为什么 glVertexAttribPointer 不直接使用缓冲区对象,而是需要这种绑定 + 调用机制,那也是因为遗留 API 的缺陷。当缓冲区对象首次被引入时,它们的设计旨在尽可能少地影响 API。因此,旧版本 glVertexAttribPointer 只是根据是否绑定了某些东西来改变其行为 GL_ARRAY_BUFFER 。如今,由于如果没有任何东西绑定到,这个函数就会失败 GL_ARRAY_BUFFER,这简直就是一个烦恼。
这样,您就可以在初始化期间尽早设置 VAO,然后只需绑定它并调用渲染函数即可绘制对象。以这种方式使用 VAO 时请注意:VAO 不是 _ 不可 _ 变的。调用上述任何函数都会更改存储在 VAO 中的数据。
索引绘图
在上一个教程中,我们绘制了一个长方体。如果您仔细查看顶点数据,您可能会注意到很多顶点数据经常重复。要绘制立方体的一个面,我们需要有 6 个顶点;两个共享顶点(沿着两个三角形之间的共享线)必须两次出现在缓冲区对象中。
对于像我们这样的简单情况,这只会稍微增加顶点数据的大小。顶点数据的紧凑形式可以是每个面 4 个顶点,或总共 24 个顶点,而我们使用的扩展版本总共需要 36 个顶点。但是,当查看具有数千甚至数百万个顶点的真实网格(例如类人角色等)时,共享顶点在性能和内存大小方面都会带来巨大好处。在许多情况下,删除重复数据可以将顶点数据的大小缩小 2 倍或更多。
为了删除这些无关的数据,我们必须执行 _ 索引绘制 ,而不是我们迄今为止一直在做的 _ 数组绘制。在之前的教程中,我们将 glDrawArrays 概念性地定义为以下伪代码:
例 5.1. 绘制数组实现
void glDrawArrays(GLenum type, GLint start, GLint count)
{
for(GLint element = start; element < start + count; element++)
{
VertexShader(positionAttribArray[element], colorAttribArray[element]);
}
}这定义了 _ 数组绘制的 _ 工作方式。您从缓冲区中的特定索引(由 start 参数定义)开始,然后按顶点向前推进 count。
为了在多个三角形之间共享属性数据,我们需要某种方法来随机访问属性数组,而不是按顺序访问它们。这可以通过 _ 元素数组 (也称为 _ 索引数组) 来实现。
假设您有以下属性数组数据:
位置数组:Pos0、Pos1、Pos2、Pos3 颜色数组:Clr0、Clr1、Clr2、Clr3
您可以使用 glDrawArrays 将前 3 个顶点渲染为三角形,或将后 3 个顶点渲染为三角形(使用 start1 和 count3)。但是,使用正确的元素数组,您可以仅从这 4 个顶点渲染 4 个三角形:
元素数组:0、1、2、0、2、3、0、3、1、1、2、3
这将导致 OpenGL 生成以下顶点序列:
(Pos0,Clr0),(Pos1,Clr1),(Pos2,Clr2), (Pos0,Clr0),(Pos2,Clr2),(Pos3,Clr3), (Pos0,Clr0),(Pos3,Clr3),(Pos1,Clr1), (位置 1,位置 1),(位置 2,位置 2),(位置 3,位置 3),
12 个顶点,生成 4 个三角形。
多个属性和索引数组
只有 _ 一个 _ 元素数组,从数组中获取的索引用于顶点数组的 _ 所有 _ 属性。因此,您不能为位置设置一个元素数组,为颜色设置一个单独的元素数组;它们都必须使用相同的元素数组。
这意味着特定属性数组中可能存在重复,而且经常会出现重复。例如,为了获得固定的面颜色,我们仍然必须为该三角形的每个位置复制颜色。并且,具有不同颜色的两个三角形之间共享的角位置仍然必须在不同的顶点中复制。
事实证明,对于大多数网格来说,这种重复是相当罕见的。大多数网格的表面都很平滑,因此不同的属性通常不会从一个位置跳到另一个位置。共享边通常对沿边的两个三角形使用相同的属性。我们使用的简单立方体等是少数几个每个属性索引具有显著优势的情况之一。
现在我们了解了索引绘制的工作原理,我们需要知道如何在 OpenGL 中设置它。索引绘制需要两件事:正确构造的元素数组和使用新的绘制命令进行索引绘制。
元素数组,正如您可能猜到的那样,存储在缓冲区对象中。它们有一个特殊的缓冲区对象绑定点。GL_ELEMENT_ARRAY_BUFFER 您可以使用此缓冲区绑定点对缓冲区对象进行正常维护(使用 glBufferData 等分配内存),就像一样 GL_ARRAY_BUFFER。但它对 OpenGL 也有特殊含义:只有当缓冲区对象绑定到此绑定点时,索引绘制才有可能,并且元素数组来自此缓冲区对象。
OpenGL 中的所有缓冲区对象都是相同的,无论它们绑定到哪个目标;缓冲区对象可以绑定到多个目标。因此,使用同一个缓冲区对象来存储顶点属性和元素数组(以及,仅供参考,OpenGL 中存在的任何其他缓冲区对象使用的数据)是完全合法的。显然,不同的数据将位于缓冲区的不同区域中。
为了进行索引绘图,我们必须将缓冲区绑定到 GL_ELEMENT_ARRAY_BUFFER,然后调用 glDrawElements。
void **glDrawElements**( | GLenum 模式, |
| GLsizei 计数, | |
| GLenum 类型, | |
GLsizeiptr 索引 ); |
第一个参数与 glDrawArrays 的第一个参数相同。该 count 参数定义从元素数组中提取多少个索引。该 type 字段定义元素数组中索引的基本类型。例如,如果索引存储为 16 位无符号短整型 (GLushort),则此字段应为 GL_UNSIGNED_SHORT。这允许用户自由使用他们想要的任何大小的索引。GL_UNSIGNED_BYTE 和 GL_UNSIGNED_INT(32 位) 也是允许的;索引必须是无符号的。
最后一个参数是索引数据开始的元素数组的字节偏移量。索引数据(以及顶点数据)应始终与其大小对齐。因此,如果我们使用 16 位无符号短整型作为索引,则应 indices 为偶数。
该函数可以通过以下伪代码定义:
例 5.2. 绘制元素实现
GLvoid * 元素数组; void glDrawElements (GLenum 类型, GLint 计数, GLenum 类型, GLsizeiptr 索引) { GLtype ourElementArray = (type)((GLbyte *)elementArray + indices); 对于(GLint 元素索引 = 0;元素索引 < 计数;元素索引 ++) { GLint 元素= ourElementArray [elementIndex]; VertexShader(位置属性数组 [元素],颜色属性数组 [元素]); } }
代表 elementArray 绑定到的缓冲区对象 GL_ELEMENT_ARRAY_BUFFER。
多个对象
教程项目 Overlap No Depth 使用 VAO 绘制两个单独的对象。这些对象使用索引绘制进行渲染。此设置展示了一种将多个对象的属性数据存储在单个缓冲区中的方法。
在本教程中,我们将绘制两个对象。它们都是楔形,尖端朝向观看者。它们之间的区别在于,一个在屏幕上是水平的,另一个是垂直的。
着色器与之前相比基本没有变化。我们使用上一个教程中的透视矩阵着色器,并进行了修改以保留场景的纵横比。唯一的区别是预摄像机偏移值;在本教程中,它是一个完整的 3D 矢量,它允许我们在场景中定位每个楔形。
初始化已更改,允许我们在启动时创建一次 VAO,然后使用它们进行渲染。初始化代码如下:
例 5.3。 VAO 初始化
void InitializeVertexArrayObjects () { glGenVertexArrays(1,&vaoObject1); glBindVertexArray(vaoObject1);
size_t colorDataOffset = sizeof ( float ) * 3 * numberOfVertices;
glBindBuffer(GL_ARRAY_BUFFER,vertexBufferObject);
glEnableVertexAttribArray( 0 );
glEnableVertexAttribArray( 1 );
glVertexAttribPointer(0,3,GL_FLOAT,GL_FALSE , 0,0 );
glVertexAttribPointer( 1 , 4 , GL_FLOAT, GL_FALSE, 0 , ( void *)colorDataOffset );
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER,indexBufferObject);
glBindVertexArray( 0 );
glGenVertexArrays(1,&vaoObject2);
glBindVertexArray(vaoObject2);
size_t posDataOffset = sizeof ( float ) * 3 * (numberOfVertices/ 2 ) ;
颜色数据偏移 += sizeof ( float ) * 4 * (numberOfVertices/ 2 ) ;
//使用之前绑定到 GL_ARRAY_BUFFER 的相同缓冲区对象。
glEnableVertexAttribArray( 0 );
glEnableVertexAttribArray( 1 );
glVertexAttribPointer( 0 , 3 , GL_FLOAT, GL_FALSE, 0 , ( void *)posDataOffset );
glVertexAttribPointer( 1 , 4 , GL_FLOAT, GL_FALSE, 0 , ( void *)colorDataOffset );
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER,indexBufferObject);
glBindVertexArray( 0 );
}
这段代码看起来很复杂,但实际上它只是我们之前见过的渲染代码。glVertexAttribPointer 由于将 2 个对象的数据存储在单个缓冲区中,因此调用的偏移计算更加复杂。但总体而言,它是相同的代码。
代码生成 2 个 VAO,绑定它们,然后设置它们的状态。回想一下,虽然绑定 GL_ARRAY_BUFFER 不是 VAO 状态的一部分,但 GL_ELEMENT_ARRAY_BUFFER 绑定 _ 是 _ 该状态的一部分。因此,这些 VAO 存储属性数组数据和元素缓冲区数据;除了实际的绘制调用之外,渲染每个对象所需的一切。
在这种情况下,两个对象使用相同的元素缓冲区。但是,由于元素缓冲区绑定是 VAO 状态的一部分,因此 _ 必须 _ 单独将其设置到每个 VAO 中。请注意,我们只设置 GL_ARRAY_BUFFER 一次绑定,但 GL_ELEMENT_ARRAY_BUFFER 会为每个 VAO 设置。
如果你查看数组中的顶点位置属性,我们有一个 3 分量位置向量。但着色器仍然使用 vec4。这是可行的,因为 OpenGL 将填充着色器寻找但属性数组未提供的任何缺失的顶点属性分量。它用零填充它们,但第四个分量除外,它用 1.0 填充。
虽然初始化代码已经扩展,但是渲染代码非常简单:
例 5.4. VAO 和索引渲染代码
gl清除颜色(0.0f,0.0f,0.0f,0.0f);
glClear(GL_COLOR_BUFFER_BIT);
glUseProgram(该程序);
glBindVertexArray(vaoObject1);
glUniform3f(偏移Uniform,0.0f,0.0f,0.0f);
glDrawElements(GL_TRIANGLES,ARRAY_COUNT(indexData),GL_UNSIGNED_SHORT,0);
glBindVertexArray(vaoObject2);
glUniform3f(偏移Uniform,0.0f,0.0f,-1.0f);
glDrawElements(GL_TRIANGLES,ARRAY_COUNT(indexData),GL_UNSIGNED_SHORT,0);
glBindVertexArray(0);
gl使用程序(0);
glutSwapBuffers();
glutPostRedisplay();
我们绑定一个 VAO,设置它的统一数据(在本例中,是为了正确定位对象),然后我们通过调用来绘制它 glDrawElements。对第二个对象重复此步骤。
运行本教程将显示以下图像:
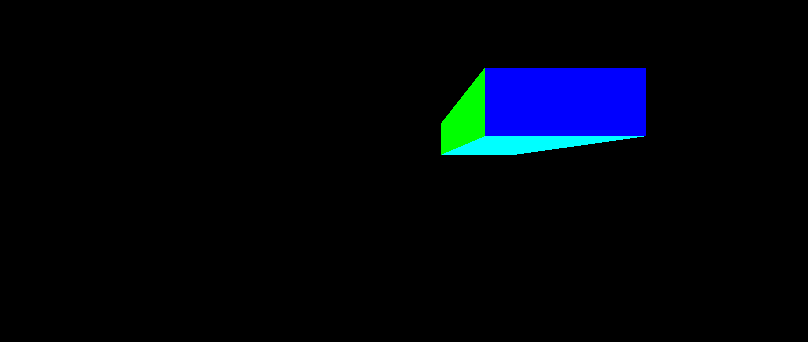
图 5.1. 重叠对象

这两个物体本质上是同一个楔形物体的翻转版本。一个物体看起来比另一个物体小,因为它距离相机的 Z 轴距离更远。我们使用透视变换,因此距离越远的物体看起来越小是有道理的。但是,如果较小的物体位于较大的物体后面,为什么它会被渲染在前面的物体之上呢?
在我们解决这个谜团之前,我们应该先解决一个小问题。