引入
给定 个二维平面上的点,求一组欧几里得距离最近的点对。
下面我们介绍一种时间复杂度为 的分治算法来解决这个问题。该算法在 1975 年由 Franco P. Preparata 提出,Preparata 和 Michael Ian Shamos 证明了该算法在决策树模型下是最优的。
过程
与常规的分治算法一样,我们将这个有 个点的集合拆分成两个大小相同的集合 ,并不断递归下去。但是我们遇到了一个难题:如何合并?即如何求出一个点在 中,另一个点在 中的最近点对?这里我们先假设合并操作的时间复杂度为 ,可知算法总复杂度为 。
我们先将所有点按照 为第一关键字、 为第二关键字排序,并以点 为分界点,拆分点集为 :
并递归下去,求出两点集各自内部的最近点对,设距离为 ,取较小值设为 。
现在该合并了!我们试图找到这样的一组点对,其中一个属于 ,另一个属于 ,且二者距离小于 。因此我们将所有横坐标与 的差小于 的点放入集合 :
结合图像,直线 将点分成了两部分。 左侧为 点集,右侧为为 点集。
再根据 规则,得到绿色点组成的 点集。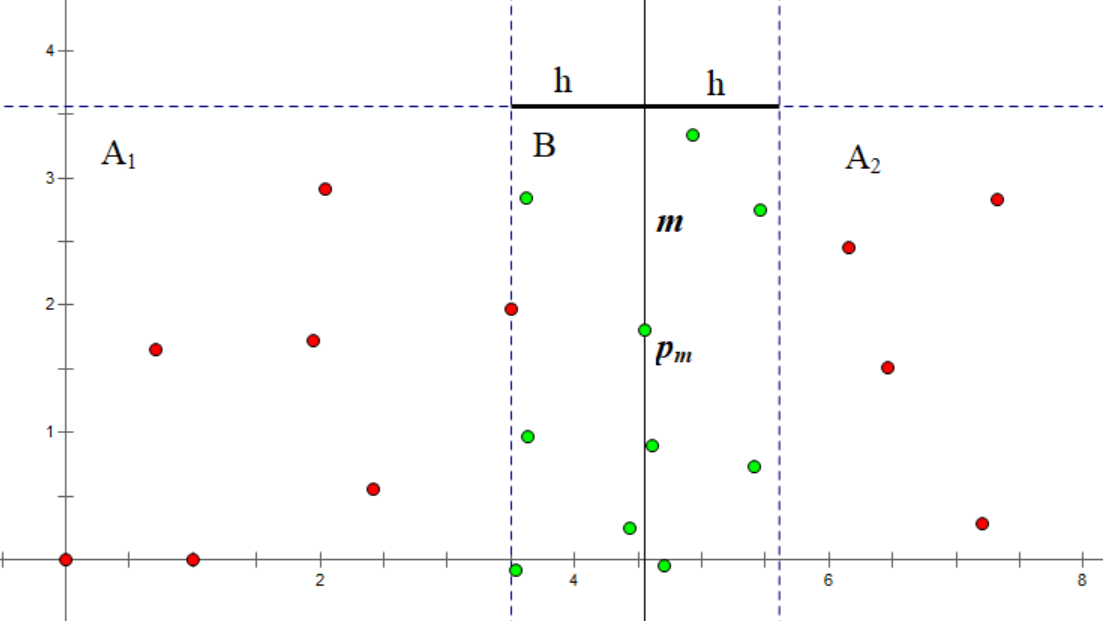
对于 中的每个点 ,我们当前目标是找到一个同样在 中、且到其距离小于 的点。为了避免两个点之间互相考虑,我们只考虑那些纵坐标小于 的点。显然对于一个合法的点 , 必须小于 。于是我们获得了一个集合 :
在点集 中选一点 ,根据 的规则,得到了由红色方框内的黄色点组成的 点集。
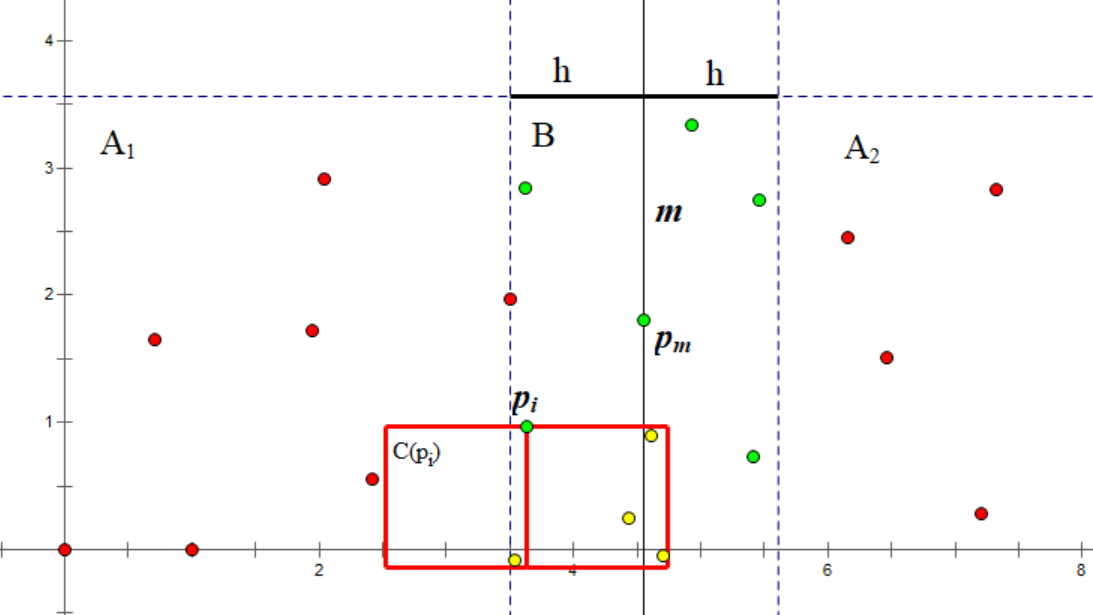
如果我们将 中的点按照 排序, 将很容易得到,即紧邻 的连续几个点。
由此我们得到了合并的步骤:
- 构建集合 。
- 将 中的点按照 排序。通常做法是 ,但是我们可以改变策略优化到 (下文讲解)。
- 对于每个 考虑 ,对于每对 计算距离并更新答案(当前所处集合的最近点对)。
注意到我们上文提到了两次排序,因为点坐标全程不变,第一次排序可以只在分治开始前进行一次。我们令每次递归返回当前点集按 排序的结果,对于第二次排序,上层直接使用下层的两个分别排序过的点集归并即可。
似乎这个算法仍然不优, 将处于 数量级,导致总复杂度不对。其实不然,其最大大小为 ,我们给出它的证明:
复杂度证明
我们已经了解到, 中的所有点的纵坐标都在 范围内;且 中的所有点,和 本身,横坐标都在 范围内。这构成了一个 的矩形。
我们再将这个矩形拆分为两个 的正方形,不考虑 ,其中一个正方形中的点为 ,另一个为 ,且两个正方形内的任意两点间距离大于 。(因为它们来自同一下层递归)
我们将一个 的正方形拆分为四个 的小正方形。可以发现,每个小正方形中最多有 个点:因为该小正方形中任意两点最大距离是对角线的长度,即 ,该数小于 。
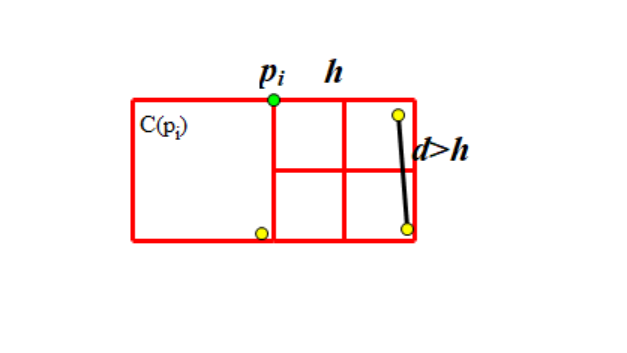
由此,每个正方形中最多有 个点,矩形中最多有 个点,去掉 本身,。
参考实现
#include <algorithm> #include <cstdio> #include <vector> using namespace std; const int N = 500000 + 10; struct point { int x, y, id; }; int n, A, B; point a[N]; // mindist 是最近距离的平方 long long mindist; // 更新答案 void upd_ans(const point& a, const point& b) { long long dist = 1LL * (a.x - b.x) * (a.x - b.x) + 1LL * (a.y - b.y) * (a.y - b.y); if (dist < mindist) { mindist = dist; A = a.id; B = b.id; } } // 使用 [l, r) 表示当前分治区间 void DC(int l, int r) { // 当前区间只有一个点,直接返回 if (l + 1 == r) return; int m = (l + r) >> 1; int midx = a[m].x; DC(l, m); DC(m, r); // 使用 std::inplace_merge() 进行归并排序 inplace_merge(a + l, a + m, a + r, [&](point a, point b) { return a.y < b.y; }); vector<point> t; for (int i = l; i < r; i++) // 距离比较时注意平方,并且比较时不取等号 if (1LL * (a[i].x - midx) * (a[i].x - midx) < mindist) t.push_back(a[i]); for (int i = 0; i < t.size(); i++) for (int j = i + 1; j < t.size(); j++) { if (1LL * (t[i].y - t[j].y) * (t[i].y - t[j].y) >= mindist) break; upd_ans(t[i], t[j]); } } void Solve() { scanf("%d", &n); for (int i = 0; i < n; i++) { scanf("%d %d", &a[i].x, &a[i].y); a[i].id = i; } // 调用前先按横坐标排序 sort(a, a + n, [&](point x, point y) { return x.x < y.x; }); mindist = 9'000'000'000'000'000'000LL; DC(0, n); printf("%d %d\n", A, B); } int main() { int T; scanf("%d", &T); while (T--) Solve(); return 0; }
推广:平面最小周长三角形
上述算法有趣地推广到这个问题:在给定的一组点中,选择三个点,使得它们两两的距离之和最小。
算法大体保持不变,每次尝试找到一个比当前答案周长 更小的三角形,将所有横坐标与 的差小于 的点放入集合 ,尝试更新答案。(周长为 的三角形的最长边小于 )
非分治算法
其实,除了上面提到的分治算法,还有另一种时间复杂度同样是 的非分治算法。
我们可以考虑一种常见的统计序列的思想:对于每一个元素,将它和它的左边所有元素的贡献加入到答案中。平面最近点对问题同样可以使用这种思想。
具体地,我们把所有点按照 为第一关键字、 为第二关键字排序,并建立一个以 为关键字的 multiset。对于每一个位置 ,我们执行以下操作:
- 将所有满足 的点从集合中删除。它们不会再对答案有贡献。
- 对于集合内满足 的所有点,统计它们和 的距离。
- 将 插入到集合中。
由于每个点最多会被插入和删除一次,所以插入和删除点的时间复杂度为 ,而统计答案部分的时间复杂度证明与分治算法的时间复杂度证明方法类似,读者不妨一试。
参考实现
#include <algorithm> #include <cmath> #include <cstdio> #include <set> using namespace std; constexpr int N = 500000 + 10; struct point { int x, y, id; point() {} bool operator<(const point& a) const { return x < a.x || (x == a.x && y < a.y); } }; int n, A, B; long long mindist; point a[N]; void upd_ans(const point& a, const point& b) { long long dist = 1LL * (a.x - b.x) * (a.x - b.x) + 1LL * (a.y - b.y) * (a.y - b.y); if (dist < mindist) { mindist = dist; A = a.id; B = b.id; } } void Solve() { scanf("%d", &n); for (int i = 0; i < n; i++) { scanf("%d %d", &a[i].x, &a[i].y); a[i].id = i; } sort(a, a + n); multiset<pair<double, point>> s; mindist = 9'000'000'000'000'000'000LL; for (int i = 0, l = 0; i < n; i++) { for (; l < i && 1LL * (a[i].x - a[l].x) * (a[i].x - a[l].x) >= mindist; l++) s.erase(s.find({a[l].y, a[l]})); // 需要注意浮点数误差 for (auto it = s.lower_bound({(double)a[i].y - sqrt(mindist) + 1e-6, point()}); it != s.end() && 1LL * (it->first - a[i].y) * (it->first - a[i].y) < mindist; it++) upd_ans(it->second, a[i]); s.insert({a[i].y, a[i]}); } printf("%d %d\n", A, B); } int main() { int T; scanf("%d", &T); while (T--) Solve(); return 0; }
期望线性做法
其实,除了上面提到的时间复杂度为 的做法,还有一种 期望 复杂度为 的算法。
首先将点对 随机打乱,我们将维护前缀点集的答案。考虑从前 个点求出第 个点的答案。
记前 个点的最近点对距离为 ,我们将平面以 为边长划分为若干个网格,并存下每个网格内的点(使用 哈希表),然后检查第 个点所在网格的周围九个网格中的所有点,并更新答案。注意到需检查的点的个数是 的,因为前 个点的最近点对距离为 ,从而每个网格不超过 个点。
如果这一过程中,答案被更新,我们就重构网格图,否则不重构。在前 个点中,最近点对包含 的概率为 ,而重构网格的代价为 ,从而第 个点的期望代价为 。于是对于 个点,该算法期望为 。
习题
- UVa 10245 “The Closest Pair Problem”[难度:低]
- SPOJ #8725 CLOPPAIR “Closest Point Pair”[难度:低]
- CODEFORCES Team Olympiad Saratov - 2011 “Minimum amount”[难度:中]
- SPOJ #7029 CLOSEST “Closest Triple”[难度:中]
- Google Code Jam 2009 Final “Min Perimeter”[难度:中]
参考资料与拓展阅读
本页面中的分治算法部分主要译自博文 Нахождение пары ближайших точек 与其英文翻译版 Finding the nearest pair of points。其中俄文版版权协议为 Public Domain + Leave a Link;英文版版权协议为 CC-BY-SA 4.0。