April Tag 定位和识别
AprilTag 介绍
AprilTag 是密歇根大学 Edwin Olson 教授及其实验团队率先提出的一个视觉基准系统,可用于各种任务,包括增强现实、机器人和相机校准。可以从普通打印机创建目标,AprilTag 检测软件可以计算标签相对于相机的精确 3D 位置、方向和标识。 官网:https://april.eecs.umich.edu/software/apriltag.html
AprilTag 论文 AprilTag: A robust and flexible visual fiducial system, ICRA 2011 AprilTag 2: Efficient and robust fiducial detection, IROS 2016 Flexible Layouts for Fiducial Tags, under review
AprilTags 在概念上类似于 QR 码,因为它们是一种二维条形码。然而,它们被设计用于编码更小的数据有效载荷(4 到 12 位之间),从而能够更可靠地从更远的距离进行检测。此外,它们专为高定位精度而设计——可以计算 出 AprilTag 相对于相机的精确 3D 位置。
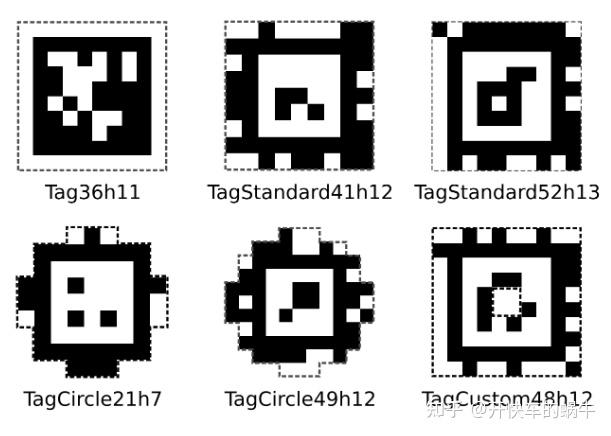
AprilTag 分类:
- TAG16H5 —> 0 to 29
- TAG25H9 —> 0 to 34
- TAG36H11 —> 0 to 586
- tagCircle21h7 —> 0 to 37
- tagCircle49h12 —> 0 to 65697
- tagCustom48h12 —> 0 to 42210
- tagStandard41h12 —> 0 to 2114
- tagStandard52h13 —> 0 to 48713
Apriltag 过程
算法步骤如下: 1)自适应阈值分割 2)查找轮廓,使用 Union-find 查找连通域 3)对轮廓进行直线拟合,查找候选的凸四边形 4)对四边形进行解码,识别 Tag 5)坐标变换,转换到世界坐标系 6)快速解码,精准定位

论文原图
图像分割
2016 年的论文里面是采用的自适应阈值进行图像分割,主要考虑了光照不均和黑暗照明对图像的影响,提高分割的准确性。自适应阈值的主要思想就是在像素领域内寻找一个合理的阈值进行分割,选取灰度均值和中值都是常见的手法。在这个基础又重要的步骤,作者采用了一个 trick,先将图像进行 4x4 网格分块,求出每个分块的灰度最大值和最小值,然后对所有分块计算的最大最小灰度值进行一个 3 邻域最大最小滤波处理,将滤波后的最大最小均值 ((max+min)/2) 作为分块区域的阈值。分块的目的主要是增加鲁棒性,区域的特征总比单一像素的更加稳定,减少随机噪声的干扰,同时提升计算效率。

自适应阈值分割
轮廓查找
通过自适应阈值后,得到一张二值图像。接下来就是要寻找可能组成 tag 标志的轮廓。连通域查找的简单方法就是计算二值图像中的黑白边缘,但是这样查找的连通域很容易出现两个 tag 公用一条边时导致连通域查找错误。因此作者采用了 union-find 算法来求连通域,每个连通域都有一个唯一的 ID。

轮廓查找
四边形检测
轮廓有了之后,对每一个轮廓进行分割,产生一个残差最小的凸四边形,作为 tag 位置的候选。这其中最难的是找四边形的四个顶点,如果对于规则的正方形或者矩形来说,其实是相对比较好做的。但是存在 tag 存在变形和仿射变化时,就有点难了。首先对无序的轮廓点按照对重心的角度进行排序,这绝对是一个很棒的 ideal。有了排序的轮廓点,然后就是按部就班的按照顺序选取距离中心点一定范围内的点进行直线拟合,不断迭代索引,计算每条直线的误差总和;对误差总和进行一个低通滤波,使系统更加鲁棒,然后选取误差总和最大的四条直线对应的角点索引作为四边形角点。然后取角点间的点拟合直线,求得四条直线的角点作为 Tag 的顶点。(这部分是最耗时的,类似于穷举,虽然是拟合直线,但是次数非常多,需重点优化的部分)。
为了得到更高精度的角点坐标,需要尽可能找到真正的梯度边缘直线。因此对直线上的点进行采样,然后计算搜索采样点在直法向量上梯度最大的点,作为最后进行直线拟合的点(图像真正的梯度边缘)。
分组遵循以下规则:前一条边的末端点应该和下一条边的始端点之间的距离小于一个阈值,并且相接的线段要构成逆时针的方向。分组成功后,所有的线段会构成一个树,该树的第一层为所有的有向线段,第二层到最后一层的节点为同一组候选者线段,应用深度优先搜索遍历整个树,若在树的深度为 4 的时候,最后一条边与第一条边构成一个闭环,则说明它们是符合二维码四边形的要求,遍历到该闭环节点的路径就构成了该四边形。

寻找四边形
坐标变换
采用单应变换将找到的四边形映射成规则正方形,这么做为了解码的需要和求解姿态。
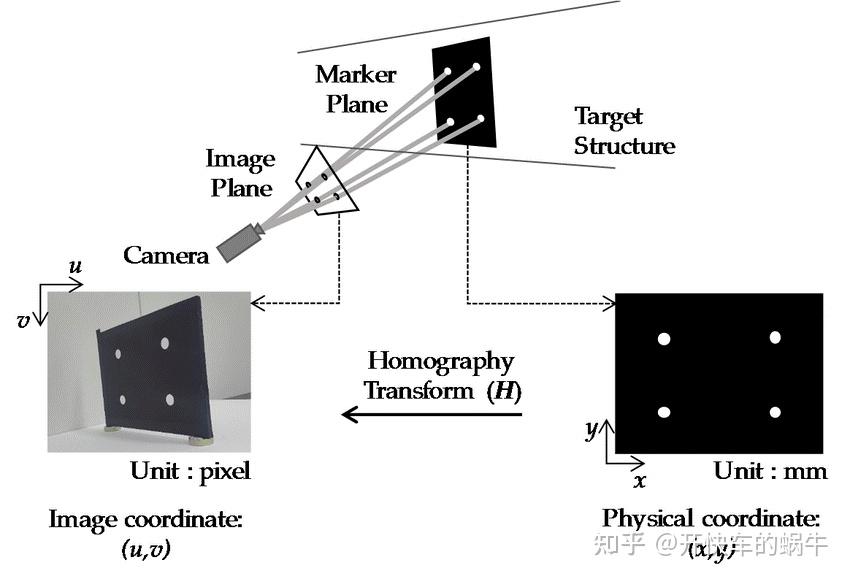
单应变换原理图
求解对应点之间的一个坐标变换。对于每一个对应的点对,都应该存在如下关系(公式 2-1),理论点坐标等于变换矩阵乘以实际图像点坐标。
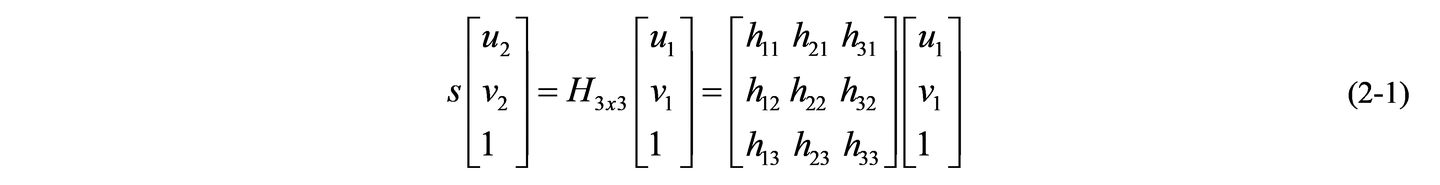
将公式(2-1)展开得到公式(2-2):
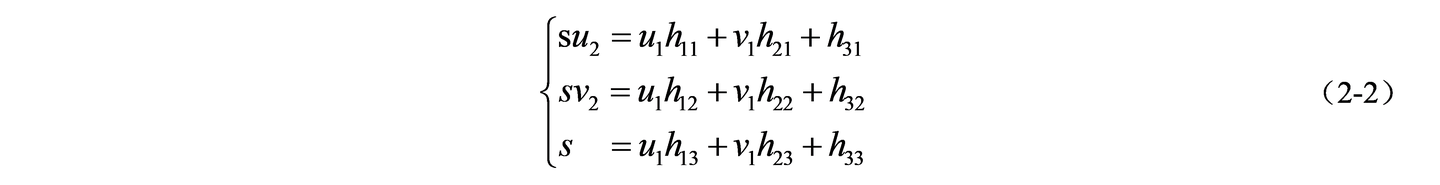
进一步变换,消去尺度因子 s,并将 H 矩阵的元素看做一个列向量,可得到公式(2-3):
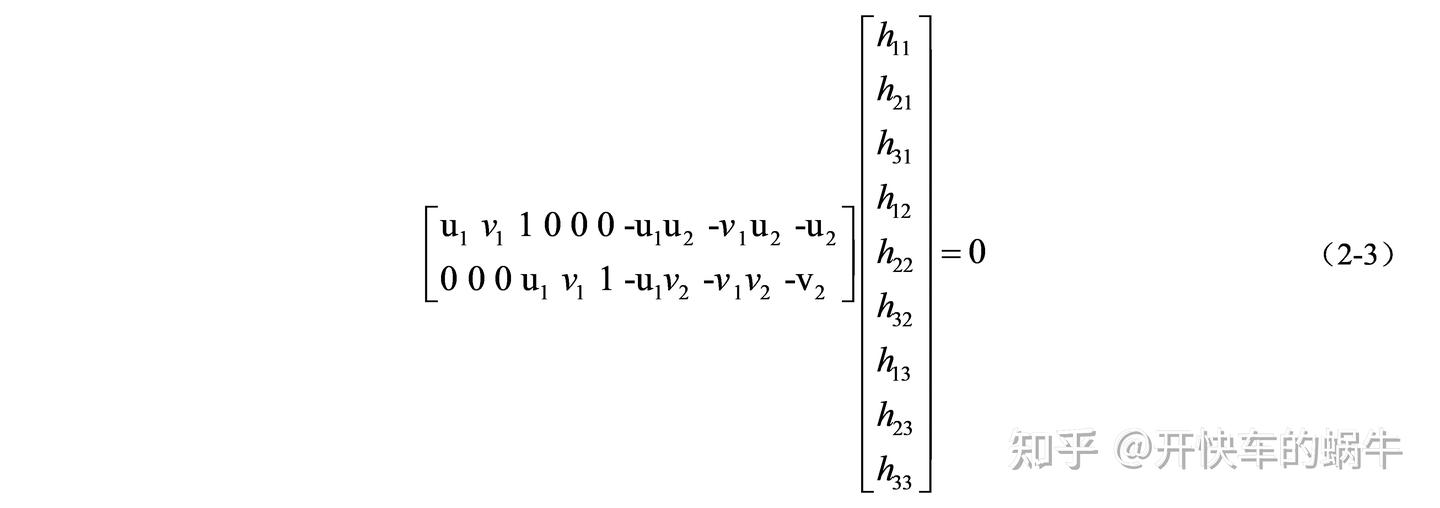
因为存在尺度因子的影响,H 矩阵最后一个元素可以归一化成 1,因此 H 矩阵的自由度为 8。为了得到公式(2-3)的解,至少需要 4 个点对,采用直接线性化可以求出上述方程,得到单应矩阵 H。
快速解码
在二维码的解码过程中,首先将二维码中每一块的坐标通过单应性矩阵映射到图像平面,判断图像平面上映射后的点的像素值是否大于某一个阈值,若大于该阈值,二维码这个坐标上为 1,相反,小于该阈值则判定为 0。然后将检测到的代码与标签序列中的每个代码进行异或。判断是否为正确的标签。
python 代码
安装 apriltag 库:window 平台 pip3 install pupil-apriltags,linux 平台 pip3 install apriltags。
pupil_apriltags 库是对纯 C 的 AprilTag 库的 python 封装;AprilTag 开源库基于 C,不依赖其他第三方库,BDS 开源。可以很容易地包含在其他应用程序中,也可以移植到嵌入式设备上。即使在手机级处理器上也可以实现实时性能。
该算法库十分方便只需两个函数。
# 创建检测器
detector = Detector(searchpath=['apriltags'],
families='tag36h11',
nthreads=1,
quad_decimate=1.0,
quad_sigma=0.0,
refine_edges=1,
decode_sharpening=0.25,
debug=0)参数:
- families – 标记族,用空格分隔,默认值:tag36h11
- nthreads – 线程数,默认值:1
- quad_decimate – 可以在较低分辨率的图像上检测四边形, 以牺牲姿态准确性和略微降低检测为代价来提高速度 率。二进制有效负载的解码仍以全分辨率完成,默认值:2.0
- quad_sigma – 应将什么高斯模糊应用于分割图像(使用 用于四边形检测?参数是以像素为单位的标准偏差。非常吵 图像受益于非零值(例如 0.8),默认值:0.0
- refine_edges – 当不为零时,每个四边形的边缘被调整为“捕捉 到“附近的强坡度。这在使用抽取时很有用,因为它 可以大大提高初始四边形估计的质量。一般 建议在(1)上。计算成本非常低。选项被忽略 如果 quad_decimate = 1,则默认值:1
- decode_sharpening – 应该对解码后的图像进行多少锐化?这 可以帮助解码小标签,但在奇怪的照明条件下可能有帮助,也可能没有帮助,或者 弱光条件,默认值 = 0.25
- debug – 如果为 1,则保存调试映像。运行速度非常慢,默认值:0
- searchpath – Apriltag 3 库地址,必须是一个列表, 默认值:[“src/lib”, “src/lib64”]
# 检测识别AprilTag码
tags = detector.detect(img,
estimate_tag_pose=False,
camera_params=None,
tag_size=None)如果还要提取标记姿势,则应将 estimate_tag_pose 设置为 True,并应提供 camera_params([fx, fy, cx, cy])和 tag_size(以米为单位)
detect 方法返回一个 Detection 对象列表,每个对象都具有以下属性(请注意,带星号的对象仅在 estimate_tag_pose=True 时计算):
- tag_family – 返回标记族。
- tag_id – 标记的解码 ID。
- hamming – 纠正了多少个错误位?注意:接受大量更正的错误会导致误报率大大增加。注意:自此实施之日起,检测器无法检测 hamming 距离大于 2 的标签。
- decision_margin – 二进制解码过程质量的衡量标准:数据位强度与决策阈值之间的平均差异。数字越大,大致表示解码越好。这是检测准确性的合理衡量标准,仅适用于非常小的标签,而对于较大的标签无效(我们可以在位单元内的任何位置进行采样,但仍然能得到良好的检测。
- homography – 描述从“理想”标签(角位于(-1,1)、(1,1)、(1,-1)和(-1,-1))到图像中像素的投影的 3x3 单应矩阵。
- center – 以图像像素坐标表示的检测中心。
- corners – 图像像素坐标中标记的角。它们总是逆时针绕在标签周围。
- pose_R* – 姿态估计的旋转矩阵。
- pose_t* – 姿态估计的偏移
- pose_err* – 估计的对象空间误差。
实例代码:
import cv2
import pupil_apriltags
img = cv2.imread("1.png", 1)
cv2.imshow("img", img)
res = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
detector = pupil_apriltags.Detector(families='tag25h9')
tags = detector.detect(res)
print(tags)
for tag in tags:
cv2.polylines(img, [tag.corners.astype(int).reshape((-1, 1, 2))],
True, (0, 255, 0), 2)
cv2.putText(img, str(tag.tag_id), (int(tag.center[0]), int(tag.center[1])),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.imshow("res", img)
cv2.waitKey()
原图

识别结果
返回结果:
[Detection object:
tag_family = b'tag25h9'
tag_id = 1
hamming = 0
decision_margin = 42.14239501953125
homography = [[ 1.12724863e+02 5.51032257e+00 4.58000187e+02]
[-3.58208802e+01 1.30018832e+02 3.08773287e+02]
[ 1.57915815e-02 1.46322976e-02 1.00000000e+00]]
center = [458.00018736 308.7732871 ]
corners = [[351.19277954 475.16384888]
[559.22167969 391.07327271]
[564.5602417 142.76806641]
[350.42633057 221.30839539]]
pose_R = None
pose_t = None
pose_err = None
, Detection object:
tag_family = b'tag25h9'
tag_id = 1
hamming = 0
decision_margin = 40.9686393737793
homography = [[ 8.50190390e+01 6.44516937e+00 2.21898797e+02]
[ 4.01879281e+01 1.31240844e+02 3.00973638e+02]
[-2.24729789e-02 1.83767688e-02 1.00000000e+00]]
center = [221.89879734 300.97363805]
corners = [[137.69992065 376.64086914]
[314.65188599 474.34542847]
[313.26965332 218.86114502]
[129.90248108 129.01638794]]
pose_R = None
pose_t = None
pose_err = None
]